---
## **Ceph Block Storage**
### **Technical Post Mortem of OTG0054944**
-----------
**Dan van der Ster, IT-ST**
*IT-ASDF, 5 March 2020*
---
### Timeline of Feb 20, 2020
* 10:11 Ceph Block Storage cluster detects 25% of OSDs down.
* OpenStack Cinder volume IOs are stopped.
* 10:20 Start investigations:
* `ceph-osd` daemons which crashed aren't able to restart.
* Log files showing crc errors in the `osdmap`.
* 12:30 Checking with community: IRC + mailing list + bug tracker.
* 13:30 Problem + workaround understood (at a basic level).
* ~17:30 Critical power service restored.
* ~19:00 Main room service restored.
---
### Ceph Internals: The OSDMap
* `ceph-osd`: Object Storage Daemon, normally one per disk.
* Ceph servers and clients share a small `osdmap`, updated incrementally between peers, which describes the state of the OSDs. Example from a tiny cluster:
```
epoch 1046
fsid d0904571-9eea-4423-9744-e74d0497ab39
created 2020-02-25 09:04:29.839366
modified 2020-02-26 19:05:08.964030
flags sortbitwise,recovery_deletes,purged_snapdirs
crush_version 10
require_min_compat_client jewel
min_compat_client jewel
require_osd_release mimic
pool 1 'lz4' replicated size 1 min_size 1 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 1046 flags hashpspool,full stripe_width 0
max_osd 3
osd.0 up out weight 0 up_from 7 up_thru 39 down_at 0 last_clean_interval [0,0) 137.138.62.86:6800/11079 137.138.62.86:6801/11079 137.138.62.86:6802/11079 137.138.62.86:6803/11079 exists,up d4ad48a2-b742-4e1a-8d0f-f822e619d4ae
osd.1 up out weight 0 up_from 11 up_thru 42 down_at 0 last_clean_interval [0,0) 137.138.62.86:6804/11650 137.138.62.86:6805/11650 137.138.62.86:6806/11650 137.138.62.86:6807/11650 exists,up 6d7b570b-cf00-46b8-84f7-98b4f2ff0612
osd.2 up in weight 1 up_from 314 up_thru 314 down_at 313 last_clean_interval [309,312) 137.138.62.86:6809/693245 137.138.62.86:6810/693245 137.138.62.86:6811/693245 137.138.62.86:6812/693245 exists,full,up 77604165-9970-433a-b7c9-fdb859923e30
```
----
* The `osdmap` contains all of the information needed for clients and servers to read and write data, and how to recover from OSD failures.
* There are functions to decode and encode an `osdmap` between its serialized and `OSDMap` class form.
---
### The Crash
* ~350 OSDs (out of 1300) all crashed when an incremental `osdmap` arrived from the network:
```
8: (OSDMap::decode(ceph::buffer::list::iterator&)+0x160e) [0x7ff6204f668e]
9: (OSDMap::decode(ceph::buffer::list&)+0x31) [0x7ff6204f7e31]
10: (OSD::handle_osd_map(MOSDMap*)+0x1c2d) [0x55ab8ca9a24d]
11: (OSD::_dispatch(Message*)+0xa1) [0x55ab8caa4361]
12: (OSD::ms_dispatch(Message*)+0x56) [0x55ab8caa46b6]
```
* *And* they refuse to restart -- they crash when loading the `osdmap` from disk:
```
8: (OSDMap::decode(ceph::buffer::list::iterator&)+0x160e) [0x7ffbbf06868e]
9: (OSDMap::decode(ceph::buffer::list&)+0x31) [0x7ffbbf069e31]
10: (OSDService::try_get_map(unsigned int)+0x4f8) [0x562efc272f38]
11: (OSDService::get_map(unsigned int)+0x1e) [0x562efc2dc00e]
12: (OSD::init()+0x1def) [0x562efc27e92f]
```
----
* It's a crc32c error in the osdmap:
```
Feb 20 10:22:08 X ceph-osd[2363469]: what(): buffer::malformed_input: bad crc, actual
3112234676 != expected 60187512
```
----
* To recover, we can extract a good `osdmap` from elsewhere and overwrite it:
```
# ceph osd getmap -o osdmap.2982809 2982809
# ceph-objectstore-tool --op set-osdmap --data-path
/var/lib/ceph/osd/ceph-666/ --file osdmap.2982809
```
* Doing this repeatedly across all affected OSDs, across several corrupted maps, brought the cluster back online.
----
* We were also able to extract a corrupted `osdmap` to compare with a good copy.
* How many bit flips can you find?
```
7467c7467
< 00020080 ff 01 00 05 00 30 0a 83 00 18 00 00 00 00 00 00 |.....0..........|
---
> 00020080 ff 01 00 05 00 30 0a 83 00 18 00 00 00 00 01 00 |.....0..........|
7469c7469
< 000200a0 00 ec 00 00 00 00 01 00 00 13 01 00 00 55 01 00 |.............U..|
---
> 000200a0 00 ec 00 00 00 01 01 00 00 13 01 00 00 55 01 00 |.............U..|
7833,7834c7833,7834
< 00021e10 00 18 00 00 00 00 00 00 00 09 00 00 00 11 00 00 |................|
< 00021e20 00 d4 00 00 00 e1 00 00 00 ec 00 00 00 00 01 00 |................|
---
> 00021e10 00 18 00 00 00 00 01 00 00 09 00 00 00 11 00 00 |................|
> 00021e20 00 d4 00 00 00 e1 00 00 00 ec 00 00 00 01 01 00 |................|
```
---
### Root Cause Theories
* Bit flips, in general, can have three different sources:
* Uncorrectable memory errors
* Packet corruption
* Software bugs
----
* Could it be a memory issue?
* We searched all servers' IPMI `elist` and `dmesg` output: no evidence of ECC errors
* Moreover, it is not obvious how a memory error could propagate across so many servers simultaneously
----
* Could it be packet corruption?
* TCP checksums are [notoriously weak](https://cds.cern.ch/record/2026187?ln=en): Ceph uses crc32c to strengthen its messaging layer.
* Also it seems extremely unlikely that an identical packet corruption would have hit all servers at the same time
* and it is not clear how a single error could propagate.
----
* There were indeed some TCP checksum errors observed during the outage, but correlation != causation!

----
* Evidence points to a software issue. But what exactly?
* It must be extremely rare -- only 2 other similar reports across thousands of clusters.
* Some initial clues:
* There are two types of on-disk formats in our Ceph OSDs:
* FileStore and BlueStore -- only BlueStore was affected.
* Info from other sites: In a mixed SSD+HDD cluster, only SSDs were affected.
* Upstream recently found a race condition updating OSDMap `shared_ptr`.
* Let's have a look at the guilty code...
----
### `OSD::handle_osd_map`
* When an `inc_map` message arrives, it is processed in `handle_osd_map`, which is pretty simple:
1. An `inc_map` message arrives (crc is good). :one:
2. Read the previous full `osdmap` from disk.
* and `decode` it, which also checks the crc. :two:
3. Apply the incremental changes to the previous full OSDMap.
4. `encode` to a new `osdmap`, validating the crc again. :three:
5. Write the new `osdmap` (serialized) to disk.
----
* From the backtraces, we know the following:
* We get an incremental map, apply and store it. :white_check_mark:
* We validate crc's at least three times!
* Next incremental map 1sec later, we try to re-read the map we just stored -> crc error :x:
* So something must be corrupting the `osdmap` after we `encode` it but before the bits are persisted on disk.
----
* We studied the "race condition" theory and the signature seemed unlikely to be related.
* So focus moved down the stack to bluestore itself.
---
### More deep thoughts.
* Let's look again at the hexdiff. Notice anything?
```
7467c7467
< 00020080 ff 01 00 05 00 30 0a 83 00 18 00 00 00 00 00 00 |.....0..........|
---
> 00020080 ff 01 00 05 00 30 0a 83 00 18 00 00 00 00 01 00 |.....0..........|
7469c7469
< 000200a0 00 ec 00 00 00 00 01 00 00 13 01 00 00 55 01 00 |.............U..|
---
> 000200a0 00 ec 00 00 00 01 01 00 00 13 01 00 00 55 01 00 |.............U..|
```
----
* Look at the address:
* `0x20000` is 128kB -- the corruptions suspiciously nearby that notable power of 2.
* And that reminds me of something:
* `bluestore_compression_min_blob_size_hdd: 131072`
* Could it be compression?
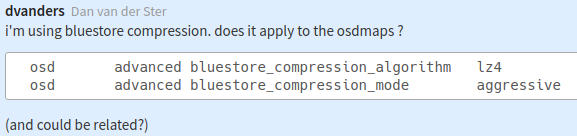
----
* Let's ask the other sites if they're using compression:
* Are you using compression? Yes, lz4, aggressive.
* Which OS? CentOS 7, Ubuntu 18.04.
---
### LZ4

* At CERN we enabled lz4 compression in December 2019 -- block storage is highly compressible so we can save ~50%!
* Tuesday after our outage we disabled lz4 compression for newly written data.
----
### Reproducing the Corruption
* It's non-trivial to reproduce the corruption:
* BlueStore breaks the file into 128kB blobs, then compresses and stores each blob individually.
* But doing exactly this does not yet reproduce.
----
### A new ceph unittest.
* To reproduce the bug, we need to load our good `osdmap` from disk, `decode` it, `encode` a new serialized map, then compress it.
* This [testunit](https://github.com/ceph/ceph/pull/33584/commits/1b1c71a2c28c38d3e28f006b1cb164435a653c02) reproduces the corruption bit for bit with real life.
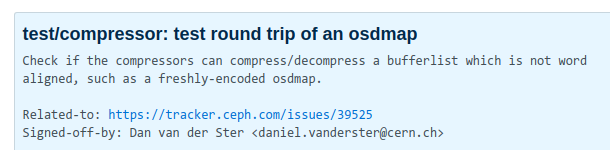
* zlib, snappy, zstd all pass. lz4 fails.
---
### Word-Alignment
* The thing we're compressing is not always a nice contiguous `char[]`. It can be fragmented and unaligned:
```
1: [ RUN ] Compressor/CompressorTest.round_trip_osdmap/0
1: [plugin lz4 (lz4)]
1: orig length 612069
1: chunk 131072 compressed 46345 decompressed 131072 with lz4
1: FAILED, fbl was
1: buffer::list(len=612069,
1: buffer::ptr(0~3736 0x5588651c97d0 in raw 0x5588651c97d0 len 4024 nref 2),
1: buffer::ptr(0~55540 0x5588651ca7e0 in raw 0x5588651ca7e0 len 55544 nref 1),
1: buffer::ptr(3736~288 0x5588651ca668 in raw 0x5588651c97d0 len 4024 nref 2),
1: buffer::ptr(0~10988 0x5588651f7850 in raw 0x5588651f7850 len 10992 nref 2),
1: buffer::ptr(3020~15 0x5588651f18bc in raw 0x5588651f0cf0 len 4024 nref 8),
1: buffer::ptr(0~1156 0x5588651fa3b0 in raw 0x5588651fa3b0 len 1444 nref 2),
1: buffer::ptr(3035~4 0x5588651f18cb in raw 0x5588651f0cf0 len 4024 nref 8),
1: buffer::ptr(1473~2550 0x5588651e8951 in raw 0x5588651e8390 len 4024 nref 7),
1: buffer::ptr(0~12 0x5588651face0 in raw 0x5588651face0 len 16 nref 2),
1: buffer::ptr(4023~1 0x5588651e9347 in raw 0x5588651e8390 len 4024 nref 7),
1: buffer::ptr(0~12 0x5588651fde60 in raw 0x5588651fde60 len 16 nref 2),
1: buffer::ptr(4020~4 0x5588651fddd4 in raw 0x5588651fce20 len 4024 nref 4),
1: buffer::ptr(4021~3 0x5588651feed5 in raw 0x5588651fdf20 len 4024 nref 4),
1: /root/git/ceph/src/test/compressor/test_compression.cc:192: Failure
1: Value of: decompressed.contents_equal(chunk)
1: Actual: false
1: Expected: true
1: [ FAILED ] Compressor/CompressorTest.round_trip_osdmap/0, where GetParam() = "lz4" (9 ms)
```
----
* So we thought: lz4 has an issue compressing unaligned data.
* `lz4-1.7.5-3.el7` specifically. Newer lz4 in Fedora does not.
* The lz4 dev `@Cyan4973` has a nice [blog post](http://fastcompression.blogspot.com/2015/08/accessing-unaligned-memory.html) from 2015 about fast access to unaligned memory.
* So is it unaligned memory? Is this a new bug? What's going on?
* As a final sanity check, we pinged `@Cyan4973` on GitHub.
> Wow, nope, that's new to me. - @Cyan4973
----
* We tried a few suggestions from Cyan4973, but nothing changed the corruption.
* Then Sage bisected to find exactly which commit "fixes" it:
* [`af12733 fixed frametest error`](https://github.com/lz4/lz4/commit/af127334670a5e7b710bbd6adb71aa7c3ef0cd72)
> This fix is applicable to requesting LZ4 to build from data scattered in memory while still maintaining history between them.
> Consolidating input as a single contiguous buffer is bound to improve the situation.
----
* A proposed lz4 workaround in Ceph will detect a fragmented bufferlist and consolidate it before compressing.
* BTW, client data should be unaffected -- client data is a large single buffer.
* The `osdmap` encoding complexity leads to its fragmentation
* even still it takes millions of `osdmap`s to find one which breaks lz4.
* [`compressor/lz4: work around bug in liblz4 versions <1.8.2`](https://github.com/ceph/ceph/pull/33584/)
---
### Next Steps
* All software and services are fallible. Including those libraries you depend upon and which works 99.999999999% of the time.
* For Ceph at CERN, we learned an immense lesson related to service dependencies.
* Without any significant outages in 6 years, thousands of services have built a dependence on a single Ceph cluster.
* Going forward, we will introduce block storage availability zones.
* Requires cooperation between several groups.
---
### Thanks and Credits
* To the Ceph firefighters: Theo Mouratidis and Julien Collet.
* To several colleagues who helped talk through the issue:
* Enrico Bocchi, Roberto Valverde, Jan Iven, Pablo Llopis, Arne Wiebalck, Jan van Eldik, Herve Rousseau, Andreas Peters, and others...
* To the Ceph community who set us on the right path:
* `dirtwash` on IRC who pointed to a related tracker 20 minutes after our outage: https://tracker.ceph.com/issues/39525
* Troy and Erik who have seen this crash before and helped with clues.
* Sage Weil (Ceph) and Yann Collet (LZ4) for their expert input and fixes.
---

#### Google SRE Book: Service Level Objectives
---
# ?
---
{"type":"slide","slideOptions":{"transition":"slide","theme":"cern5"},"slideNumber":true,"title":"2020-03-05 - Ceph Post Mortem","tags":"presentation, ASDF"}