<!--
This slide is blank to show the CERN logo.
Hit "s" during presentation for speaker mode (see the notes).
-->
Note:
Empty Slide to show the CERN Logo
---
### Automation of (Remediation) procedures for Batch Services @ CERN
<!-- ##### + other updates -->
<!-- EXTERNAL IMAGE LINK -->
<style>
.reveal section img {
border: none;
box-shadow: none;
}
</style>
#### powered by </span>
---
##### Ankur Singh <<ankur.singh@cern.ch>> IT-CD-CC
---
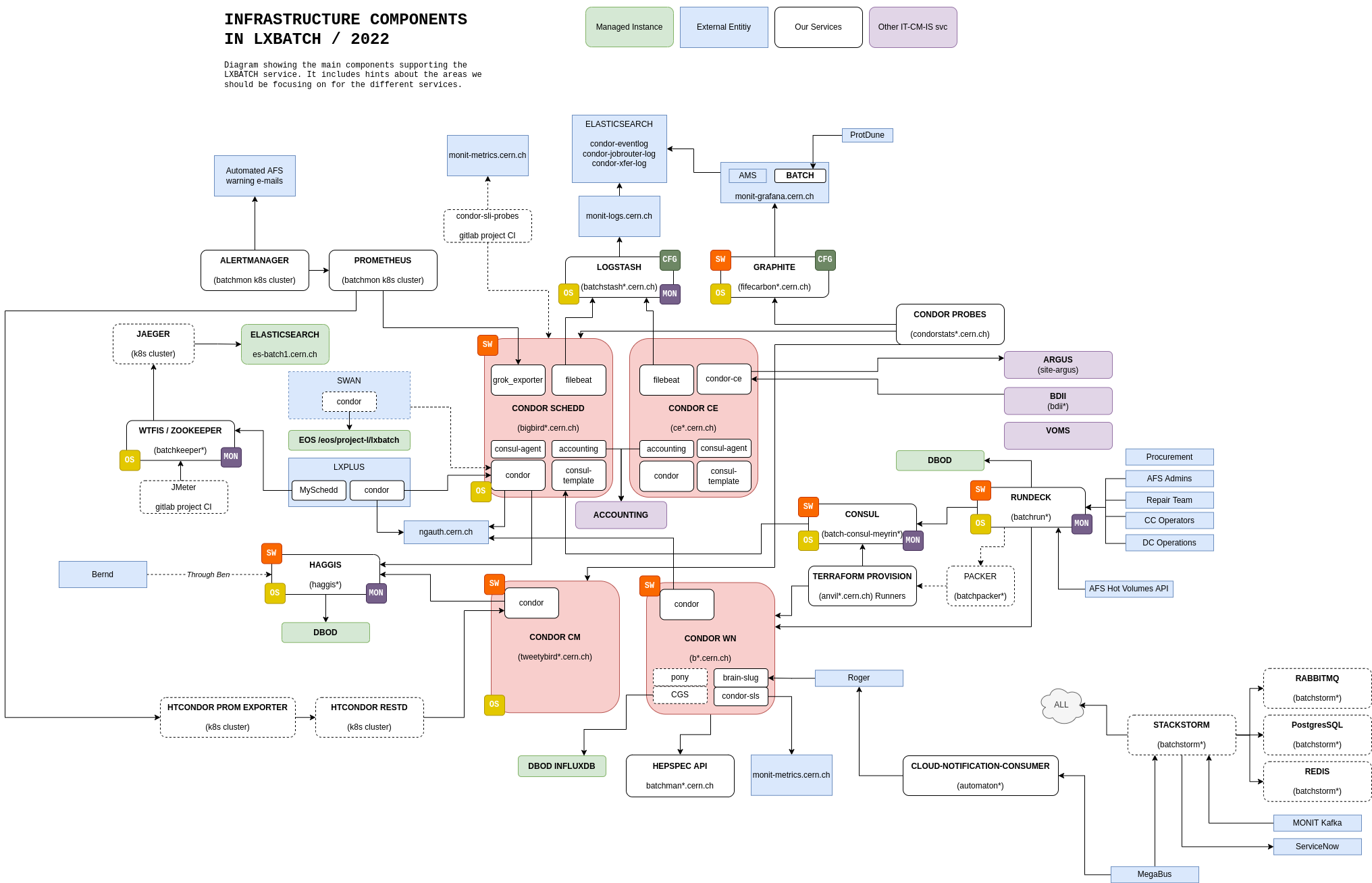
## Batch Services at CERN
#### Batch Services ~= 265k cores (3.4MHS06)
#### in ~2 HTCondor pools
#### 300-350 daily active submitters
##### 20 Local schedds / 22 Grid CEs
#### == managing ~5000 servers
###### with ~10 humans and a lot active shell sessions
----
#### More details
- Currently fully bare-metal with OpenStack Ironic (15k VMs -> 5k Ironic)
- Machines are built and added into a OpenStack project by DC and Cloud teams
- Terraform is used for provisioning the worker nodes
- Puppet + CERN AI (Agile Infrastructure) Tools install and configure the machine
- Rundeck is used to provide a "human" entry point for frequent actions
- StackStorm is used for automatic remediation
----
### Batch is like herding cattle
#### *BUT* your cattle is
- in different places
- of different shapes and sizes
- in different physical and logical groups
- using different management systems
- running ancient code and legacy interfaces
- being pushed to its extremes

Note:
Places = DCs. Shapes/Sizes = different servers configs. Physical/Logical Groups = AZs, OS Projects, Racks, Network... Management Systems = Config and Provisioning. Ancient Code = Condor? Legacy Interfaces = AFS? Extremes = Workloads.
----
----
---
## Outcomes?
<!-- EXTERNAL IMAGE LINK -->

----
## Lots of **frequent** but **easy** issues
- Handled by 2nd-level support (or Rota)
- A lot of false positives
- (often) Requiring multi-step debugging
- (often) Solved with a service restart or reboot
- Wastes human time and energy
<!-- EXTERNAL IMAGE LINK -->

Note:
2nd-level = CC Operators in our case.
----
### While others need experts
1. Require domain knowledge and/or in-depth investigation
2. Initial diagnostics data helps
3. Low frequency for a single specific type of issue
<!-- EXTERNAL IMAGE LINK -->

Note:
1. Which makes it hard to automate
2. Which makes it easy to automate
3. Which makes it impractical/unefficient to automate
---
## So lets automate it all?
#### The easy issues are actually good candidates
- Documented procedures/know-how for a lot of tasks
- Some steps might be async
- Writing automation scripts/bots/apps for each problem is tedious/impractical
- Can benifit from common automation tooling
- Might benifit from parallelism
Note:
- Async steps means that you have to wait for a meaningful time after each action and might have to check on a status before continuing the next action
---
### BrainSlug 
Small go based state-machine daemon to control worker node state
- It instructs the worker to do basic things based on the Roger state and a basic payload shipped in the Roger message.
- Actions like "Start draining", "Stop draining", "Depending on payload, reboot if drained", "Depending on payload, transition to a different Roger state after reboot"
- For draining and rebooting multiple machines, concurrency controls are optionally available.
- These controls allow selecting which or how many machines can be draining or rebooting at the same time.
----
#### Payloads
```bash=
{
"drain": {
"targetdate": $(date +%s)
},
"power": {
"targetDate": $(( $(date +%s) + 3600 * 24 * 7 )),
"policy": "asap",
"concurrency": {
"strategy": "groupsemaphore",
"options": "tag:rack"
}
}
}
```
----
#### Basic Flow
```graphviz
digraph orchestratorview {
graph [nodesep=1]
P -> D [label="start draining" color=red fontcolor=red];
D -> REB [label="finish draining" color=red fontcolor=red];
D -> REB:w [label="drain timeout" color=red fontcolor=red];
REB -> RES [label="booted" color=red fontcolor=red];
RES -> P [label="healthcheck ok" color=red fontcolor=red];
RES -> RES [label="healthcheck fail" color=red fontcolor=red];
subgraph cluster_prod {
P [label="Production"];
label="Roger production";
color=blue;
fontcolor=blue;
style=dashed;
}
subgraph cluster_drain {
style=dashed;
color=blue;
fontcolor=blue;
D [label="Draining"];
label="Roger draining";
}
subgraph cluster_reb {
REB [label="Rebooting"];
label="Roger hard_reboot";
color=blue;
fontcolor=blue;
style=dashed;
}
subgraph cluster_res {
RES [label="Restore"];
label="Roger disabled";
color=blue;
fontcolor=blue;
style=dashed;
}
}
```
Note:
Key:
* Black arrows are transitions managed by the orchestrator
* Red arrows are transitions managed by the brainslug
* Dashed lines are operator actions
* Circled in blue are the corresponding roger machine states that could be used to match internal states.
----
#### Orchestrated Flow
```graphviz
digraph orchestratorview {
graph [nodesep=1]
P -> D [label="drain"];
D -> RES [label="restore"];
D -> REB [label="finish draining" color=red fontcolor=red];
D -> REB:w [label="drain timeout" color=red fontcolor=red];
REB -> I [label="reboot timeout"];
REB -> RES [label="booted" color=red fontcolor=red];
I -> RES:s [label="operator action" style=dashed];
RES -> P [label="healthcheck ok" color=red fontcolor=red];
RES -> I [label="healthcheck fail" color=red fontcolor=red];
subgraph cluster_prod {
P [label="Production"];
label="Roger production";
color=blue;
fontcolor=blue;
style=dashed;
}
subgraph cluster_drain {
style=dashed;
color=blue;
fontcolor=blue;
D [label="Draining"];
label="Roger draining";
}
subgraph cluster_reb {
REB [label="Rebooting"];
label="Roger hard_reboot";
color=blue;
fontcolor=blue;
style=dashed;
}
subgraph cluster_res {
RES [label="Restore"];
label="Roger disabled";
color=blue;
fontcolor=blue;
style=dashed;
}
subgraph cluster_int {
I [label="Intervention"];
label="Roger intervention";
color=blue;
fontcolor=blue;
style=dashed;
}
}
```
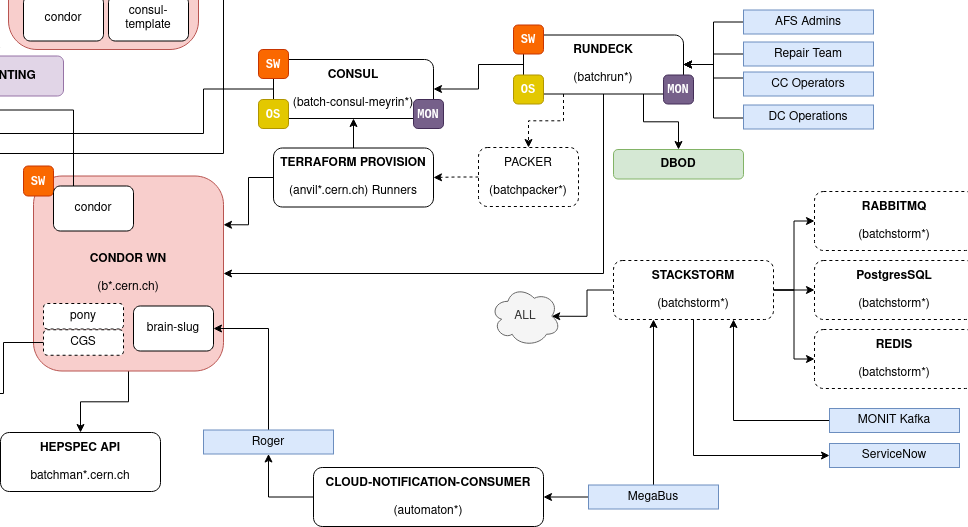
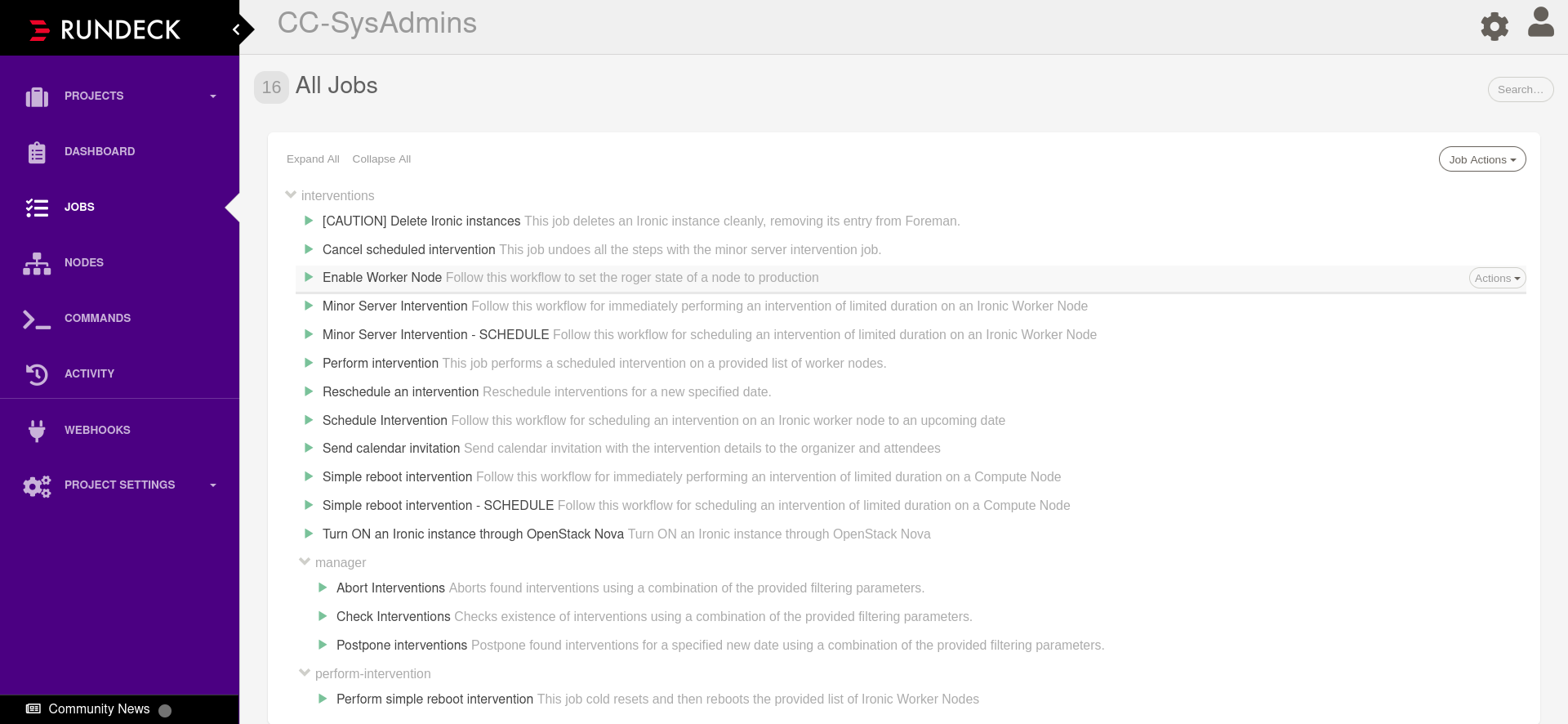
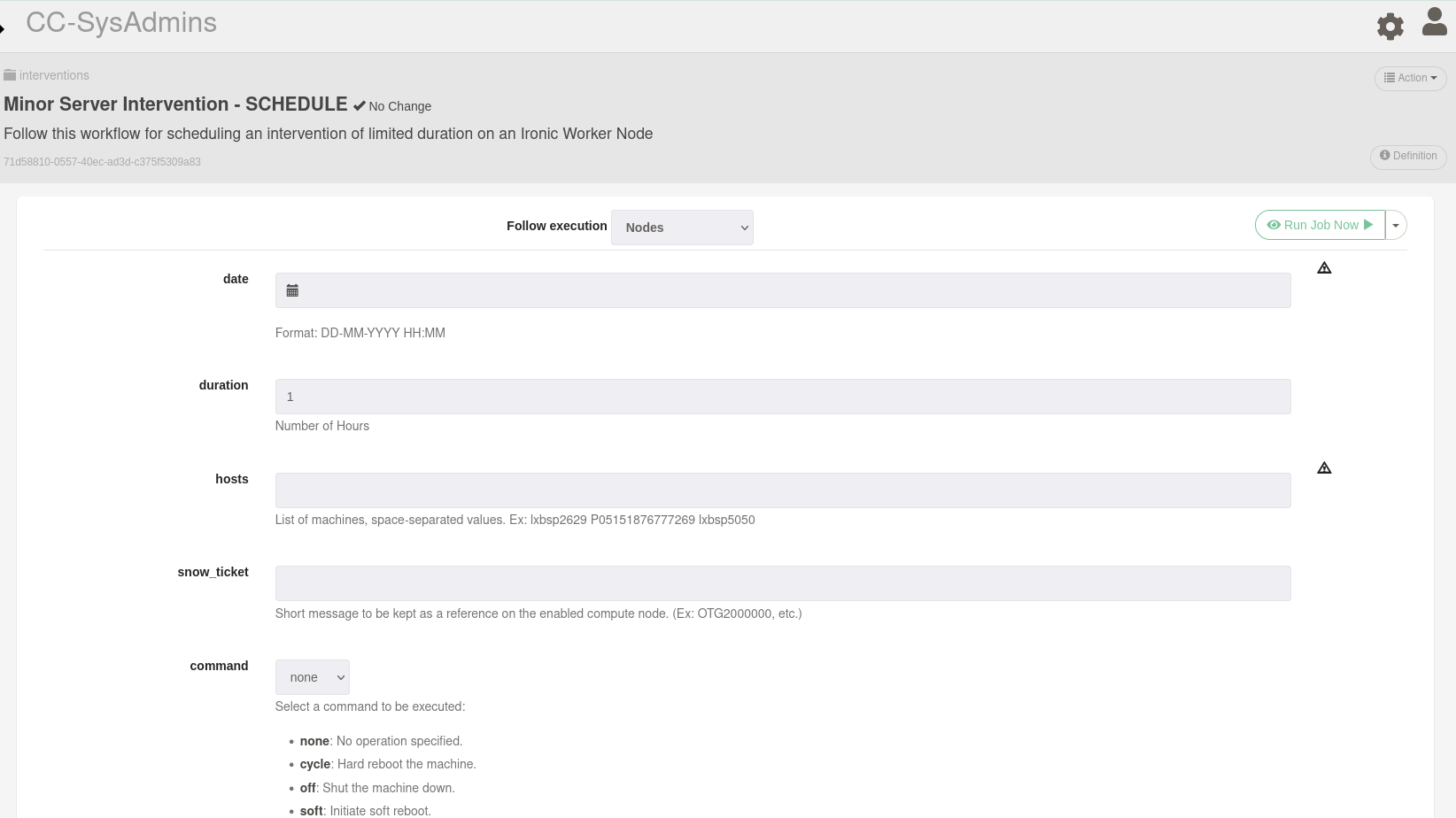
---
### 
Interface for Operators and other "humans" to interact and manage batch farms
- Interacts with other components like BrainSlug
- Drain nodes, Reboot nodes
- Schedule an intervention
----
----
---
<!-- EXTERNAL IMAGE LINK -->
## Enter 
---
##### It's like IFTTT, but for DevOps (and more)
<!-- Source: https://www.bitovi.com/web-application-consulting-services/stackstorm-consulting -->
###### and our contender for Auto-Remediation
----
### Automatic Remediation?
<!-- Source: https://www.bitovi.com/web-application-consulting-services/stackstorm-consulting -->
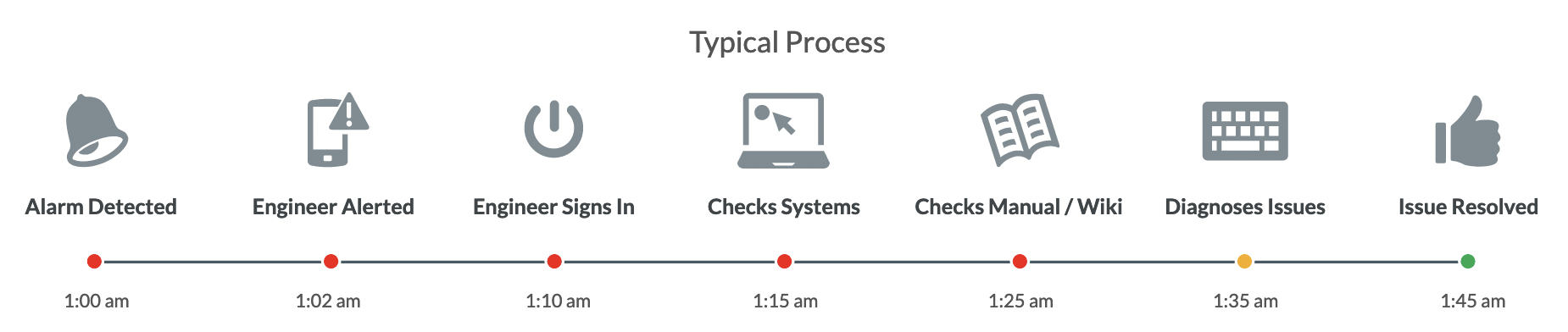
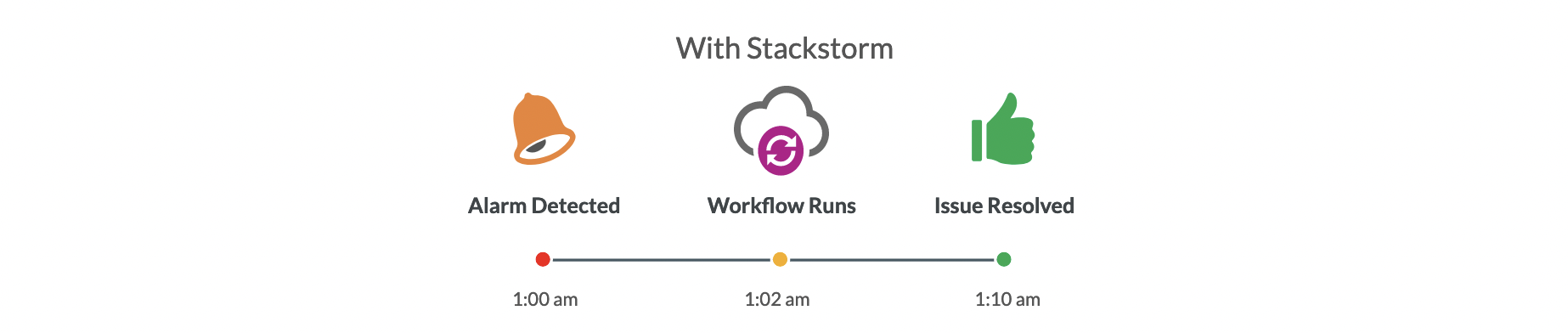
----
### What Stack? Which Storm?
- DevOps automation toolset, batteries included
- Python based, fully Open source
- Connect applications programmatically and visually
- Automation-as-Code mindset
- Reported to decrease keyboard homicide, improve developer sleep.
###### * T&C apply
----
- `Sensors` for *actionable* events
- which `Rules` route to `Actions` or `Workflows`
- `Policies` for (concurrency) control
- `Webhooks`, `Cron` and friends
- `ChatOps` baked in
- Extensible with `Packs`
- Upstream libary `Exchange`
----
<!-- Source: https://www.bitovi.com/web-application-consulting-services/stackstorm-consulting -->

----
#### It's a bunch of microservices playing nice with each other!
<!-- Source: https://docs.stackstorm.com/overview.html -->
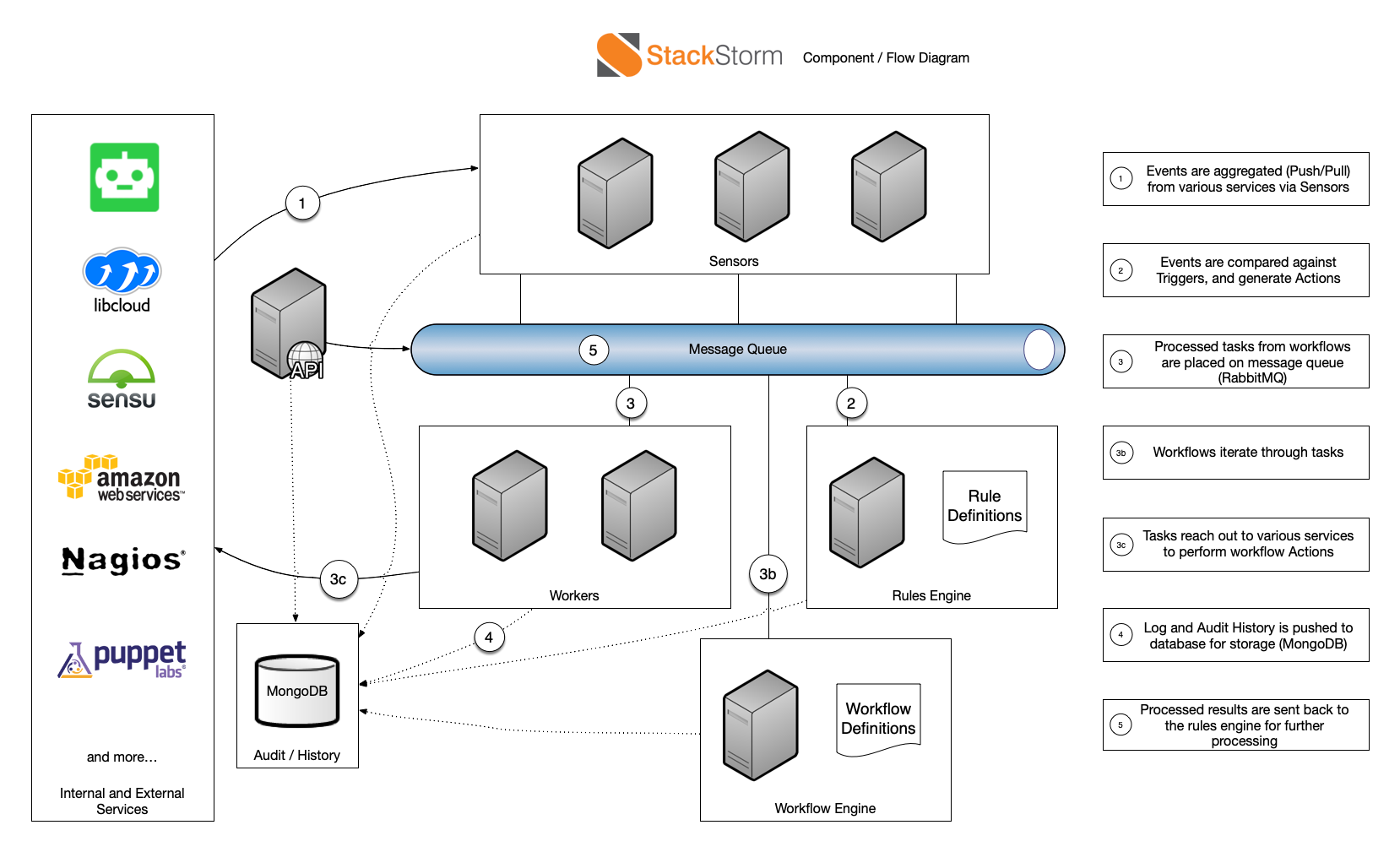
---
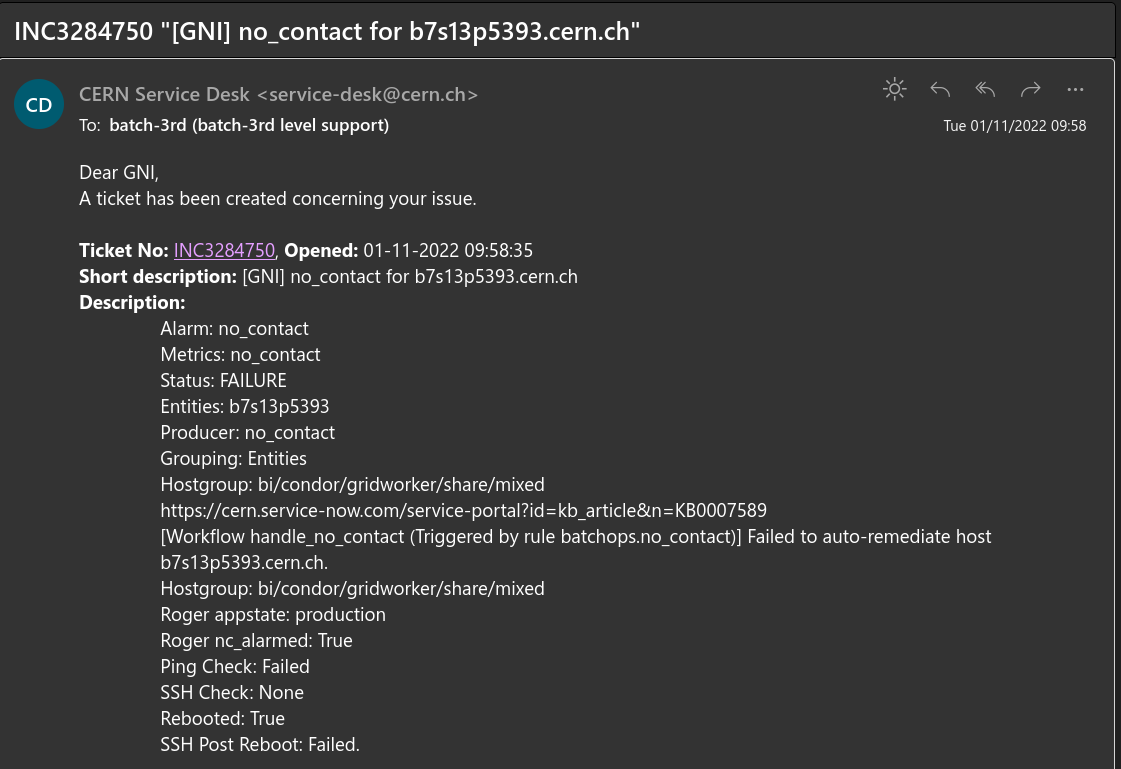
## Automating No-Contact Alarms
----
## The Problem
### Sick birds need attention
#### Unhealthy batch nodes raise (a lot of?) no_contact GNI alarms
- Assigned to CC Operators
- Given a manual to check and try to restore nodes
- https://cern.service-now.com/service-portal?id=kb_article&n=KB0007589
<!-- *Missing metrics on how many and what end-resolutions* -->
----

---
## Context

----
## Plugging in

----
## Logic
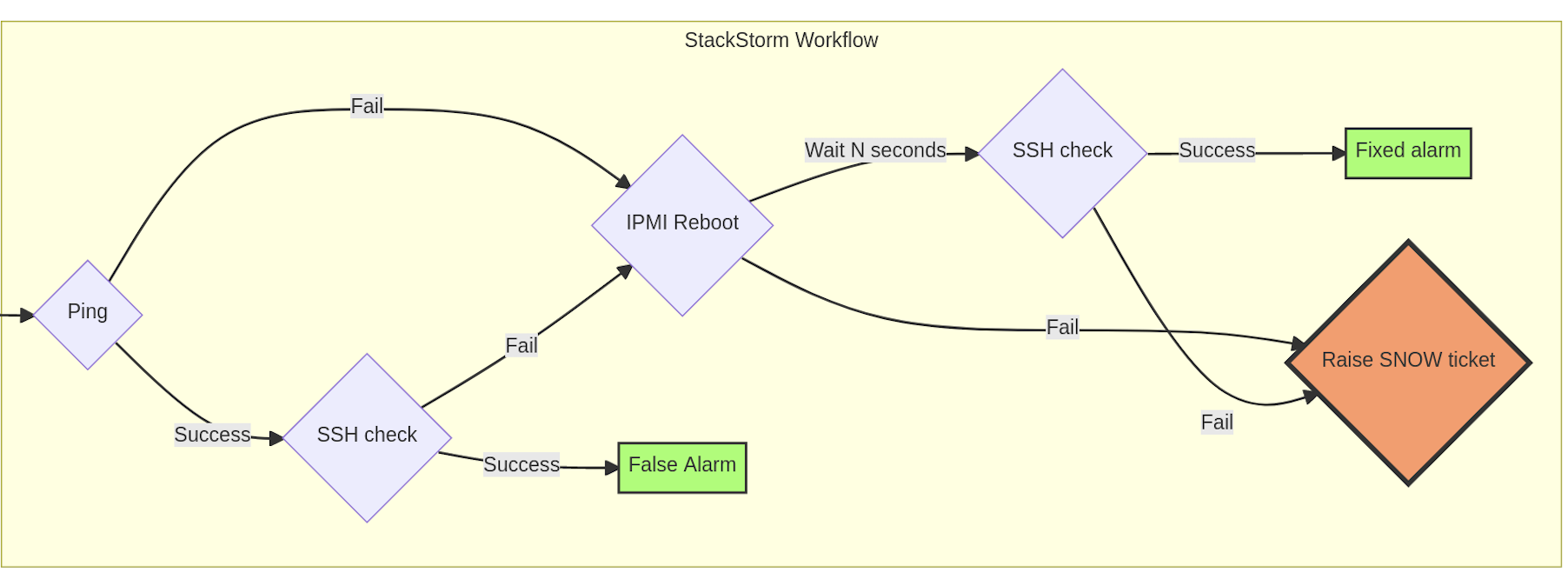
---
## Architecture
- `monit.no_contact_sensor.py` [sensor](https://gitlab.cern.ch/batch-team/stackstorm/packs/monit/-/blob/master/sensors/no_contact_sensor.py) reads monit's kafka and parse's no_contact alarms
- filters required alarms per hostgroups etc. based on config
- raises a [trigger](https://gitlab.cern.ch/batch-team/stackstorm/packs/monit/-/blob/master/sensors/no_contact_sensor.yaml#L5-36) `monit.no_contact`
- `batchops.no_contact` [rule](https://gitlab.cern.ch/batch-team/stackstorm/packs/batchops/-/blob/master/rules/no_contact.yaml) processes `monit.no_contact` trigger, matches to a `batchops.handle_no_contact` [action/workflow](https://gitlab.cern.ch/batch-team/stackstorm/packs/batchops/-/blob/master/actions/handle_no_contact.yaml)
- `batchops.handle_no_contact` [workflow](https://gitlab.cern.ch/batch-team/stackstorm/packs/batchops/-/blob/master/actions/workflows/handle_no_contact.yaml) emulates the actions of the CC Operator using StackStorm and only raises a ticket if preliminary checks fails
---
### Current state of workflow
<!--  -->

---
## Building blocks
- sensor
- `monit.no_contact_sensor`
- actions
- `aitools.pdb_facts`
- `aitools.ping`
- `aitools.ssh_uptime`
- `aitools.openstack_reboot`
- `brainslug.drain_node`
- `monit.raise_nocontact_alarm`
- `networking_utils.resolve`
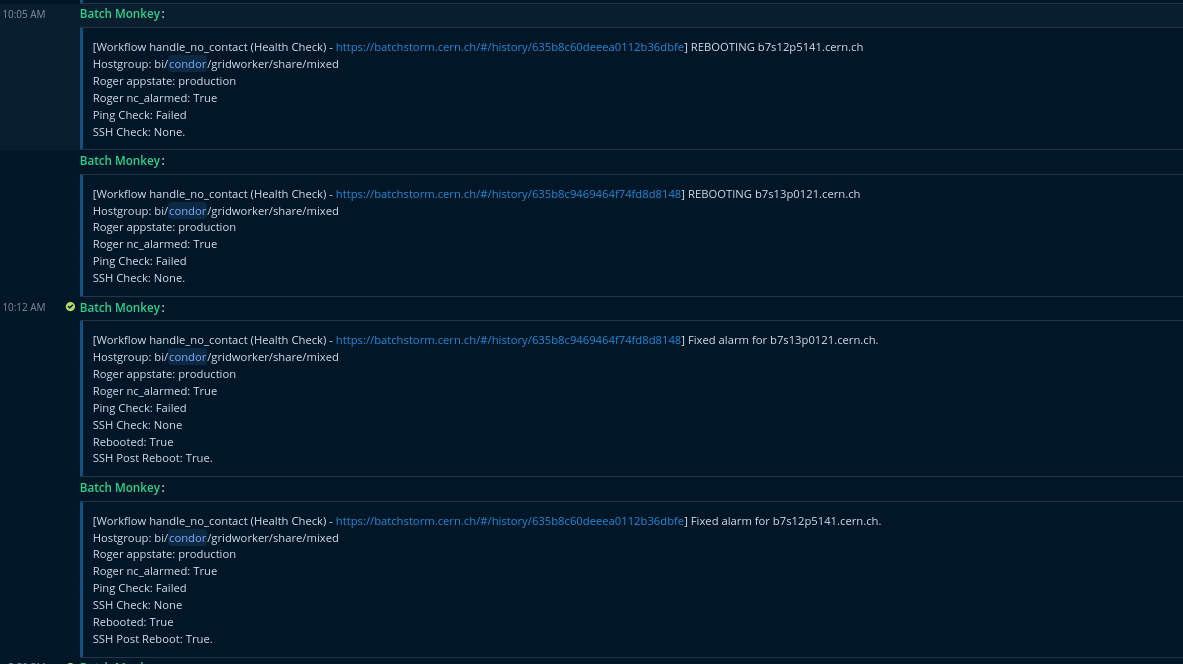
- chatops (Batch Monkey/AutomatedOps) setup
---
## Outcomes?
----
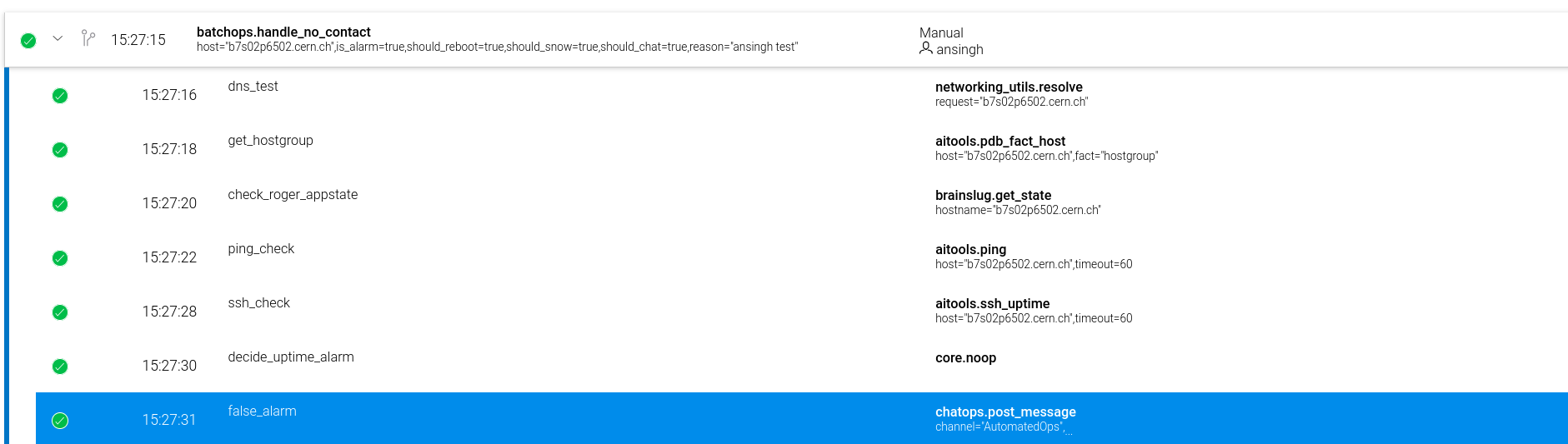
----

----
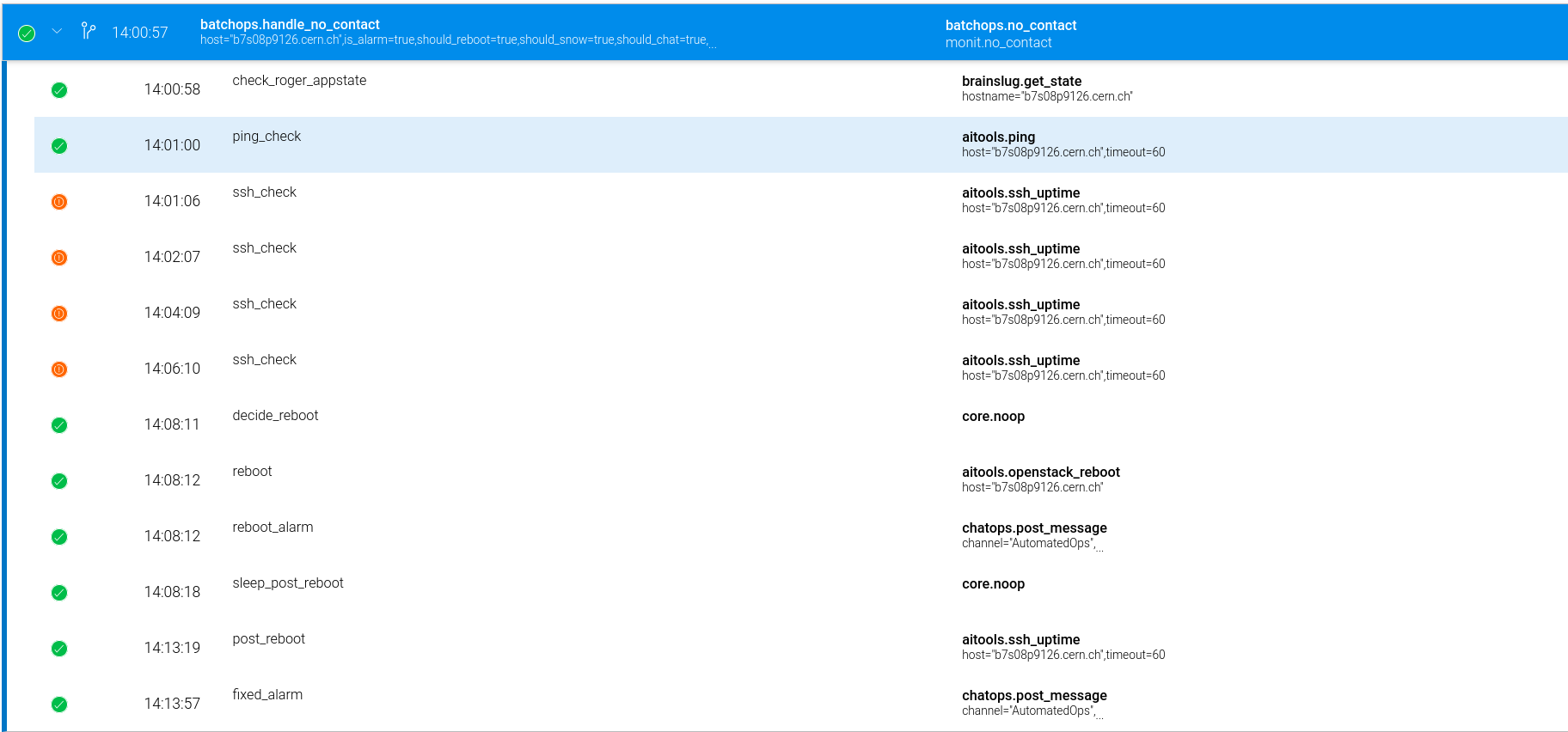
----
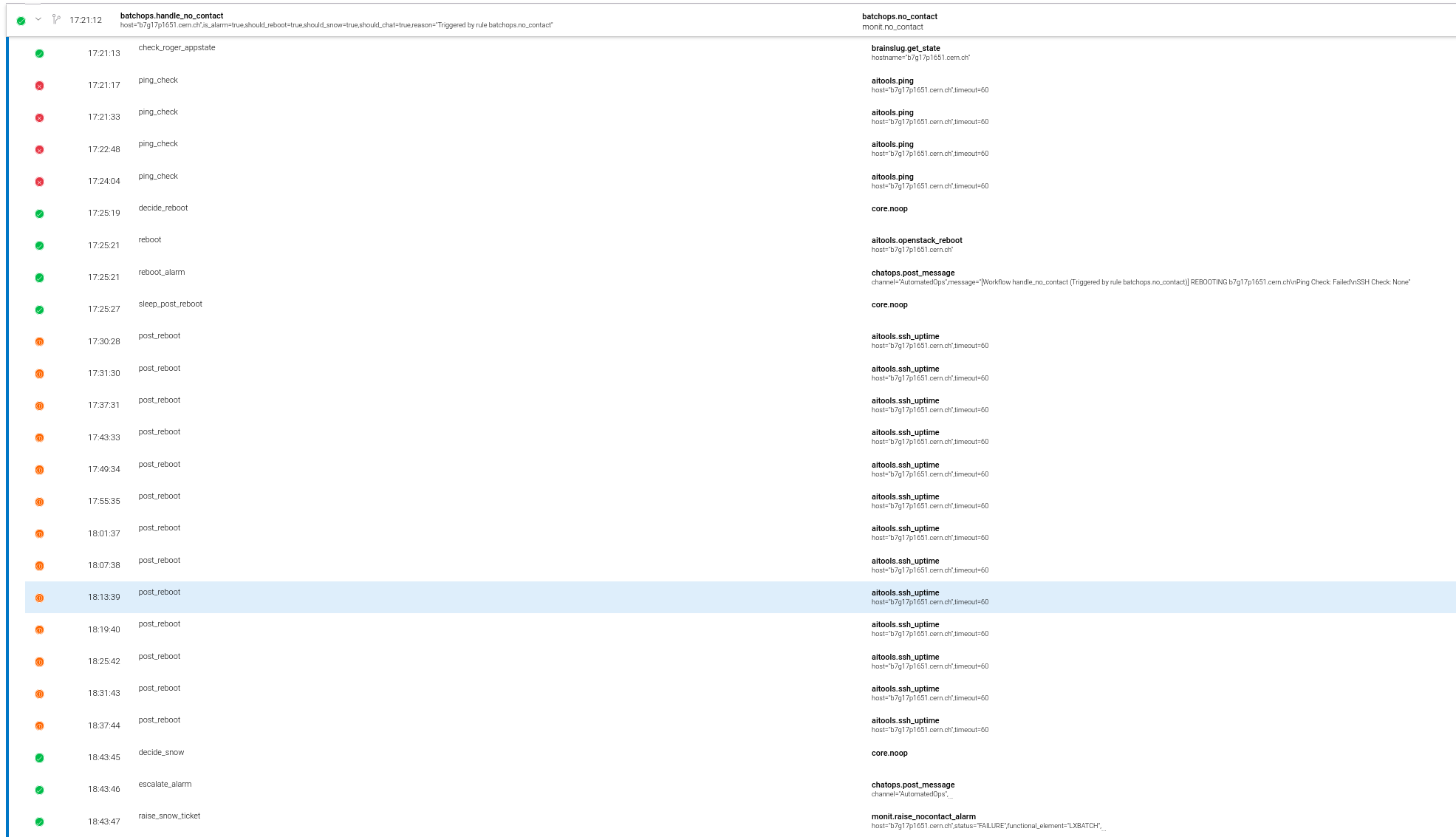
----
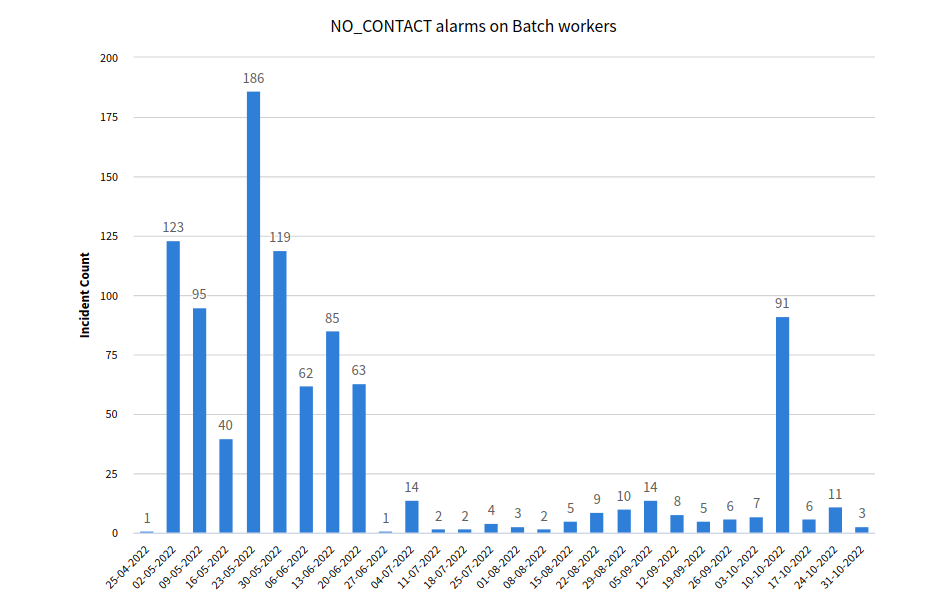
Note:
- Data since May 1st
- Slow mid Aug - early Sept was a bug
- Oct 10 peak was a Monit Outage
----

----
----

---
### Health Checks
- The no contact workflow was further adopted to perform health checks on the worker nodes
- Runs every day, checks if the nodes are properly configured and running
- Makes disaster recovery easy
----
---
## What was the experience like?
- Turning ON (destructive) automations is a risky endevaour
- have change control, log what you do
- enable dry-run like patterns to be on the safe side
- Turning off-and-on-again is just one band-aid, some times we need a first aid kit
- handle more comprehensive/edge cases for less uncertainity
- Concurrency controls are important - rebooting the whole DC is easy
- Fast iterations on workflows
---
## Perfect is it?
<!-- EXTERNAL IMAGE LINK -->

----
1. Setting up the base infra is not simple
2. Coding integrations has a small learning curve
3. While official docs are good, lacks in community docs
4. HA is not well practiced in puppet lands
5. [stackstorm-ha](https://github.com/StackStorm/stackstorm-ha) on k8s is in beta
6. Still a nascent open-source community, though active and responsive
7. Fixed dependency on MongoDB and RabbitMQ
8. Upstream packs often lack maintenance, which ends up being a fork in our repos
----
- Simple usecases are often complicated to onboard
- Collaboration can be hard while deploying PoCs
- YAML doesn't mean people already know what to write
- you have to learn a new DSL
- StackStorm offers an interesting base for development of automations
- Comes with limits and can easily be abused
- Serverless REST API with StackStorm anyone?
- Overall a mature enough product to be used by CERN
- Upstream collaboration ensures success on both ends
Note:
- Requring upstream collaboration means that we as CERN users may/will have to contribute (back) to upstream and get involved in the product development, as it still benefits from being a small and naive community
---
## Future plans
<!-- EXTERNAL IMAGE LINK -->

----
### The Good
###### It gets exponentially powerful as our base of internal integration packs expands
- Rollout more integrations and automation packs
- Setup assisted DevOps or Playbook style remediation
- Integrate with our Anomaly Detection systems as a first responder to events
- Setup proper monitoring and more friendly interfaces
- Test the scalability and reliability of the system
----
### The Bad
###### A lot of work goes in initial setup and development
- Infrastructure templates, once setup properly, can be reused and shared
- Packs can be collaboratively developed and owned
- Establish documentation and guidelines for such development
- Keep spending effort on internal development of the product to keep things smooth
- Contribute back to upstream and be involved
---
## The Dream!
<!-- EXTERNAL IMAGE LINK -->

---
## Extra Slides
---
## Why is Batch hard to maintain?
1. Multiple clusters with a heterogenous mix of resources
2. With multiple underlying (networked) filesystems
- Spinning Disks fail more often than you thought
3. Jobs are arbitrary workloads lasting upto a week
- We try to cleanup after them, but cannot be perfect
- Systems get pushed to extremes
- So things break, often!
4. A certain amount of availability is expected
5. Killing jobs to do maintanence is *undesirable*
6. Cluster management lacks central state or controls
Note:
3. Means cluster cannot loose a sizeable portion of it's capacity at once
---
### No-contact workflow code
#### Actions:
- [Raise no_contact alarm](https://gitlab.cern.ch/batch-team/stackstorm/packs/monit/-/blob/master/actions/raise_nocontact_alarm.yaml) ([Code](https://gitlab.cern.ch/batch-team/stackstorm/packs/monit/-/blob/master/actions/raise_alarm.py))
- [aitools.ping](https://gitlab.cern.ch/batch-team/stackstorm/packs/aitools/-/blob/master/actions/ping.yaml) ([Code](https://gitlab.cern.ch/batch-team/stackstorm/packs/aitools/-/blob/master/actions/ping.py))
- [aitools.ssh_uptime](https://gitlab.cern.ch/batch-team/stackstorm/packs/aitools/-/blob/master/actions/ssh_uptime.yaml) ([Code](https://gitlab.cern.ch/batch-team/stackstorm/packs/aitools/-/blob/master/actions/ssh_uptime.py))
- [brainslug.get_state](https://gitlab.cern.ch/batch-team/stackstorm/packs/brainslug/-/blob/master/actions/get_state.yaml) ([Code](https://gitlab.cern.ch/batch-team/stackstorm/packs/brainslug/-/blob/master/actions/get_state.sh))
- [aitools.openstack_reboot](https://gitlab.cern.ch/batch-team/stackstorm/packs/aitools/-/blob/master/actions/openstack_reboot.yaml) ([Code](https://gitlab.cern.ch/batch-team/stackstorm/packs/aitools/-/blob/master/actions/openstack_reboot.py))
----
### Sensor:
- [Trigger,Yaml Meta](https://gitlab.cern.ch/batch-team/stackstorm/packs/monit/-/blob/master/sensors/no_contact_sensor.yaml)
- [Python Script](https://gitlab.cern.ch/batch-team/stackstorm/packs/monit/-/blob/master/sensors/no_contact_sensor.py)
- [Config Schema](https://gitlab.cern.ch/batch-team/stackstorm/packs/monit/-/blob/master/config.schema.yaml)
- [Actual Config](https://gitlab.cern.ch/ai/it-puppet-hostgroup-batchinfra/-/blob/qa/data/hostgroup/batchinfra/automaton/stackstorm/core.yaml#L48-93)
----
### Rule
[Rule Definition](https://gitlab.cern.ch/batch-team/stackstorm/packs/batchops/-/blob/master/rules/no_contact.yaml)
### Workflow
- [Workflow (action) Meta](https://gitlab.cern.ch/batch-team/stackstorm/packs/batchops/-/blob/master/actions/handle_no_contact.yaml)
- [Workflow definition](https://gitlab.cern.ch/batch-team/stackstorm/packs/batchops/-/blob/master/actions/workflows/handle_no_contact.yaml)
----
---
### StackStorm Service Architecture
<!-- Source: https://docs.stackstorm.com/reference/ha.html -->

----
## StackStorm Services
* **st2sensorcontainer** - sensor runner - raise triggers
* **st2rulesengine** - evaluate rules against sensor triggers
* **st2timersengine** - user specified timers aka cron
* **st2scheduler** - scheduler for action runs
* **st2actionrunners** - actual actions run here
* **st2workflowengine** - workflow *engine* runner
----
### StackStorm Services (Contd.)
* **st2notifier** - monitor/sensor for action runs etc. (meta-sensors)
* **st2auth** - authentication service with a REST endpoint
* **st2api** - REST API endpoint, used by CLI, Webhooks and WebUI
* **st2stream** - HTTP endpoint for event stream (updates)
* **st2garbagecollector** - purges old execution history data from the database
---
## Abstractions
**Actions**: Outbound integrations via ssh, bash or python
**Workflows** aka. complex-action: **Series of actions** connected with flow control and shared state.
**Sensors**: Python plugins for either inbound or outbound integration that receives or watches for events respectively. Emits: **Triggers**
**Rules**: **Trigger** -> **Action**/**Workflow** mapping (IFTTT)
**Packs**: Packaging of Python code representing the **Sensors**, **Actions**, **Rules** and **Workflows** in a single namespace
----
## Actions
* Code for a single unit of work (reboot a server, fire ion cannon, drain a condor node, turn the light blue, find the AFS DDoS culprit etc.)
* Can be a Python script, HTTP request, or a shell command/script run locally or remotely
* Defined as YAML (for metadata) inside **Packs**, along with Python/Bash code to wrap the commands for the action
* Invoked manually or automatically via **Triggers** and **Workflows**
* Error handling, retrying etc. implemented and handled by st2
----
## Sensors and Triggers
- **Sensors** are Python Scripts to integrate with external systems (+YAML metadata)
- Either poll external systems (eg. Condor) periodically, or passively wait for inbound events (eg. Kafka, WebSocket)
- Dispatch **Triggers**, which are matched by **Rules**, which decide whether or not to run **Actions**
- Can ingest data from emails, message queues, monitoring etc.
- Need to be careful to only ingest actionable data here, which potentially raise a **Trigger**
- Useless data ingestion can slow down the pipeline
<!-- Examples: HTCondor, Monit -->
----
## Workflows
- StackStorm uses a custom graph based workflow engine called Orquesta
- Composer makes the execution graph from spec, Conductor directs the execution of the workflow graph
- A workflow definition is a structured YAML file that describes the intent of the workflow
- Workflow is made up of one or more **tasks**
- A task defines what action to execute (with required input) and publish output for the next **tasks**
- When a task completes, it can transition into other **tasks** based upon criteria
----
### Workflows (Contd.)
- The workflow execution graph can be a directed graph or a directed cycle graph
- It can have one or more root nodes which are the starting tasks for the workflow
- The graph can have branches that run in parallel and then converge back to a single branch
- A single branch in the graph can diverge into multiple branches
- A workflow can start other workflows
- A workflow can pause to ask for user input (**Inquiry**)
----
## Rules
* Rules map triggers to actions (or workflows), apply matching criteria and map trigger payloads to action inputs
* Can also be a timer (cron) to run an action periodically
* Acts on parameters (payload) received from triggers to evaluate the defined criteria
* If the criteria is matched, the action or workflow corresponding to the rule is invoked
----
## Packs
- A **pack** contains Actions, Workflows, Rules, Sensors bundled in a single namespace
- Acts as a logical grouping or a unit of deployment for integrations and automations
- StackStorm Exchange (https://exchange.stackstorm.org/) has a library of community contributed packs
- GitLab, Puppet, Snow, Jira, Azure, Foreman, OpenStack, Hue, Tesla, st2…
- Serve as drop in integration or as a base template
- **Packs** can read configuration defined through st2 cli or yaml files
---

---
{"type":"slide","slideOptions":{"theme":"cern4","transition":"slide"},"title":"[HEPIX Fall 2022] Automation of (Remediation) procedures for Batch Services in CERN with StackStorm ","tags":"hepix, automation, batch, devops, stackstorm"}