---
#### *Ceph Tech Talks Presents...*
-----------
### **Solving the "Bug of the Year"**
-----------
Dan van der Ster, CERN IT
#### 25 June 2020
---
The following is a story
about February 20th and the days that followed,
when our OpenStack block storage went down,
how we diagnosed and resolved the outage,
and how we finally solved,
the "bug of the year".
---
### Ceph @ CERN
* CERN is the European Centre for Nuclear Research in Geneva:
* Large Hadron Collider, the "largest machine in the world"
* Discovery of the Higgs Boson, explaining why particles have mass, leading to the Nobel Prize for Physics
* Ceph has been a key part of our IT infrastructure since 2013:
* Block storage & CephFS for OpenStack
* `s3.cern.ch` for object storage applications
* RADOS clusters for custom storage services
* In total, we operate around 10 clusters with 35PiB RAW
----
### Setting: OpenStack Cinder Volumes
* In 2013 we started offering Ceph RBD via OpenStack Cinder
* Ceph & RBD proved to be incredibly reliable over the years
* Few short outages, mostly related to network connectivity
* Over time, more and more use-cases moved to our cloud
* As of February 2020:
* Around 500 different "shared" OpenStack projects use RBD
* A/V, DBs, Repositories, Engineering, Physics, ...
* Plus more than 1200 "personal" OpenStack projects
* In total, more than 6000 Cinder volumes, 4PiB RAW used
* Two pools, two rooms: battery backup, diesel backup
---
### Timeline of Feb 20th
* 10:11 Our main rbd cluster suddenly has 25% of OSDs down
* PGs are inactive, all IOs are blocked
* 10:20 Start investigating:
* The crashed `ceph-osd` processes won't restart
* Their log files show crc errors in the `osdmap`
* 12:30 Checking with community: IRC + mailing list + bug tracker
* 13:30 Problem + workaround understood (at a basic level)
* 17:30 Diesel-backed rbd service restored
* 19:00 Battery-backed rbd service restored
---
So, what happened?
First, a bit of background.
---
### Ceph Internals: The OSDMap
* **`ceph-osd`**: Object Storage Daemon, normally one per disk
* Ceph maintains a small **`osdmap`**, describing the state of the cluster, e.g.
```
# ceph osd dump
epoch 1046
fsid d0904571-9eea-4423-9744-e74d0497ab39
created 2020-02-25 09:04:29.839366
modified 2020-02-26 19:05:08.964030
flags sortbitwise,recovery_deletes,purged_snapdirs
crush_version 10
require_min_compat_client jewel
min_compat_client jewel
require_osd_release mimic
pool 1 'mypool' replicated size 1 min_size 1 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 1046 flags hashpspool,full stripe_width 0
max_osd 3
osd.0 up out weight 0 up_from 7 up_thru 39 down_at 0 last_clean_interval [0,0) 137.138.62.86:6800/11079 137.138.62.86:6801/11079 137.138.62.86:6802/11079 137.138.62.86:6803/11079 exists,up d4ad48a2-b742-4e1a-8d0f-f822e619d4ae
osd.1 up out weight 0 up_from 11 up_thru 42 down_at 0 last_clean_interval [0,0) 137.138.62.86:6804/11650 137.138.62.86:6805/11650 137.138.62.86:6806/11650 137.138.62.86:6807/11650 exists,up 6d7b570b-cf00-46b8-84f7-98b4f2ff0612
osd.2 up in weight 1 up_from 314 up_thru 314 down_at 313 last_clean_interval [309,312) 137.138.62.86:6809/693245 137.138.62.86:6810/693245 137.138.62.86:6811/693245 137.138.62.86:6812/693245 exists,full,up 77604165-9970-433a-b7c9-fdb859923e30
```
----
* The `osdmap` contains all of the info needed for clients and servers to perform IO and recover from failures:
* osd state info, e.g. when have they been up and running, ...
* the **`crushmap`**, a description of the infrastructure (rooms, racks, hosts, osds, ...) and data placement rules
* The `osdmap` is shared via peers across the cluster
* An OSD cannot perform IO without the latest **`epoch`**, or version, of the map
* Each OSD persists recent epochs on disk
----
* Devs rely on internal functions to **`encode`** and **`decode`** an `osdmap` between a C++ **`OSDMap`** instance and its serialized form.
* Advanced Ceph operators can use **`osdmaptool`** to print and manipulate an `osdmap`
---
### Our Outage: How did the OSDs crash?
* At 10:11, around 350 OSDs (out of 1300) crashed simultaneously with this backtrace:
```
8: (OSDMap::decode(ceph::buffer::list::iterator&)+0x160e) [0x7ff6204f668e]
9: (OSDMap::decode(ceph::buffer::list&)+0x31) [0x7ff6204f7e31]
10: (OSD::handle_osd_map(MOSDMap*)+0x1c2d) [0x55ab8ca9a24d]
11: (OSD::_dispatch(Message*)+0xa1) [0x55ab8caa4361]
12: (OSD::ms_dispatch(Message*)+0x56) [0x55ab8caa46b6]
```
* **`handle_osd_map`** receives an incremental `osdmap` from a peer, then crashes in `OSDMap::decode`
----
* Making matters worse, the osds couldn't restart, giving this slightly different backtrace:
```
8: (OSDMap::decode(ceph::buffer::list::iterator&)+0x160e) [0x7ffbbf06868e]
9: (OSDMap::decode(ceph::buffer::list&)+0x31) [0x7ffbbf069e31]
10: (OSDService::try_get_map(unsigned int)+0x4f8) [0x562efc272f38]
11: (OSDService::get_map(unsigned int)+0x1e) [0x562efc2dc00e]
12: (OSD::init()+0x1def) [0x562efc27e92f]
```
* **`try_get_map`** loads the `osdmap` from disk, then crashes in `OSDMap::decode`
----
* We have a clear indication that the `osdmap` has been corrupted:
`/var/log/messages` shows a crc32c checksum error:
```
Feb 20 10:22:08 X ceph-osd[2363469]: what(): buffer::malformed_input: bad crc, actual
3112234676 != expected 60187512
```
----
* We reached out to `#ceph`, who pointed us to a related [thread](http://lists.ceph.com/pipermail/ceph-users-ceph.com/2019-August/036519.html) and [issue](https://tracker.ceph.com/issues/41240)
* This crash had been seen before, and a quick fix is known...
----
* We first extract a good, uncorrupted, copy of the `osdmap` from a mon:
```
# ceph osd getmap -o osdmap.2982809 2982809
```
* We then overwrite the corrupted version in each failed osd's objectstore:
```
# ceph-objectstore-tool --op set-osdmap --data-path
/var/lib/ceph/osd/ceph-666/ --file osdmap.2982809
```
* Doing this repeatedly across all failed OSDs, for several corrupted epochs, brought the cluster back online
---
After nearly 6 or 7 hours down, we were back online!
But questions remained...
* Why did the osdmaps suddenly get corrupted?
* Will it happen again?!
----
* To help with the root cause analysis, we diffed the valid and corrupted copies of one `osdmap`:
```
7467c7467
< 00020080 ff 01 00 05 00 30 0a 83 00 18 00 00 00 00 00 00 |.....0..........|
---
> 00020080 ff 01 00 05 00 30 0a 83 00 18 00 00 00 00 01 00 |.....0..........|
7469c7469
< 000200a0 00 ec 00 00 00 00 01 00 00 13 01 00 00 55 01 00 |.............U..|
---
> 000200a0 00 ec 00 00 00 01 01 00 00 13 01 00 00 55 01 00 |.............U..|
7833,7834c7833,7834
< 00021e10 00 18 00 00 00 00 00 00 00 09 00 00 00 11 00 00 |................|
< 00021e20 00 d4 00 00 00 e1 00 00 00 ec 00 00 00 00 01 00 |................|
---
> 00021e10 00 18 00 00 00 00 01 00 00 09 00 00 00 11 00 00 |................|
> 00021e20 00 d4 00 00 00 e1 00 00 00 ec 00 00 00 01 01 00 |................|
```
There are four single bit flips!
---
### Root Cause Theories
* Bit flips can have a few different sources:
* Uncorrectable memory errors
* Network packet corruption
* Software bugs
----
* Could it be a memory issue?
* We searched all the server IPMI `elist` and `dmesg` output: no evidence of ECC errors
* Moreover, it is not obvious how a memory error could affect so many servers simultaneously
----
* Could it be packet corruption?
* TCP checksums are [notoriously weak](https://cds.cern.ch/record/2026187?ln=en): Ceph uses crc32c to strengthen its messaging layer
* Also it seems extremely unlikely that an identical packet corruption would have hit all servers at the same time
* and it is not clear how a single error could propagate
----
* There were indeed some TCP checksum errors observed during the outage, but correlation != causation!

----
* Evidence points to a software issue. But what exactly?
* It must be extremely rare -- only 2 other similar reports across thousands of clusters
* Some initial clues:
* There are two types of on-disk formats in our Ceph OSDs:
* FileStore and BlueStore -- only BlueStore was affected
* Info from other sites: In a mixed SSD+HDD cluster, only SSDs were affected
* Upstream recently found a race condition updating OSDMap `shared_ptr`
* Could it be `osd_map_dedup`?
* Maybe compression?!
----
* Soon after we reported this, Sage suggested to disable **`osd_map_dedup`**
* Recall that each OSD caches several hundred decoded `OSDMap` epochs
* And most of the OSDMap doesn't change between epochs
* To save memory, `osd_map_dedup=true` deduplicates the decoded members, setting pointers in the current epoch to the identical values from the previous epoch.
* So we set it to `false`
------------
But let's review the relevant functions...
----
### `OSD::handle_osd_map`
* When an `inc_map` message arrives, it is processed in `handle_osd_map`, which is pretty simple:
1. An `inc_map` message arrives (crc is good) :one:
2. Read the previous full `osdmap` from disk
* and `decode` it, which also checks the crc. :two:
3. Apply the incremental changes to the previous full `OSDMap`
4. `encode` to a new `osdmap`, validating the crc again :three:
5. Write the new `osdmap` (serialized) to disk
----
* From the backtraces, we know the following:
* We get an incremental map, apply and store it. :white_check_mark:
* We validate crc's at least three times!
* Next incremental map 1sec later, we try to re-read the map we just stored -> crc error :x:
* So something must be corrupting the `osdmap` after we `encode` it but before the bits are persisted on disk.
----
* We studied the `shared_ptr` race condition theory but the signature seemed unlikely to be related
* The `osd_map_dedup` implementation is quite simple and seemed unlikely to be buggy
* So our focus moved down the stack to bluestore itself
---
#### More deep thoughts...
* Let's look again at the hexdiff. Notice anything?
```
7467c7467
< 00020080 ff 01 00 05 00 30 0a 83 00 18 00 00 00 00 00 00 |.....0..........|
---
> 00020080 ff 01 00 05 00 30 0a 83 00 18 00 00 00 00 01 00 |.....0..........|
7469c7469
< 000200a0 00 ec 00 00 00 00 01 00 00 13 01 00 00 55 01 00 |.............U..|
---
> 000200a0 00 ec 00 00 00 01 01 00 00 13 01 00 00 55 01 00 |.............U..|
```
----
* Look at the address:
* `0x20000` is 128kB -- the corruption is suspiciously nearby a power of 2.
* And that reminds me of something:
* `bluestore_compression_min_blob_size_hdd: 131072`
* "Could it be compression?"
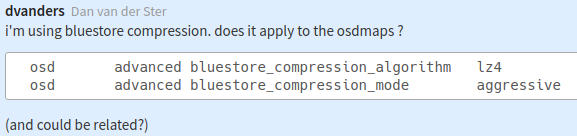
----
* Let's ask the other reporters:
* Are you using compression? Yes, lz4, aggressive.
* Which OS? CentOS 7, Ubuntu 18.04.
---
### LZ4

* At CERN we enabled lz4 compression in December 2019 -- block storage is highly compressible so we can save ~50%!
* Five days after our outage we disabled lz4 compression across the cluster
----------
How is it possible that lz4, a hugely popular algorithm that compresses most of the web, could corrupt an osdmap?
----
#### Let's try to reproducing it
* When writing, BlueStore breaks an object into 128kB blobs, then compresses and stores each blob individually
* We tried splitting the osdmaps into 128kB pieces, but couldn't reproduce any corruption during write
----
#### Going deeper... alignment and fragmented memory
* When an `osdmap` is compressed, it is not a contiguous `char[]`.
* Ceph decoders/encoders are quite memory efficient, and deduplication ensures it will be scattered in memory.
```
osdmap was
buffer::list(len=612069,
buffer::ptr(0~3736 0x5588651c97d0 in raw 0x5588651c97d0 len 4024 nref 2),
buffer::ptr(0~55540 0x5588651ca7e0 in raw 0x5588651ca7e0 len 55544 nref 1),
buffer::ptr(3736~288 0x5588651ca668 in raw 0x5588651c97d0 len 4024 nref 2),
buffer::ptr(0~10988 0x5588651f7850 in raw 0x5588651f7850 len 10992 nref 2),
buffer::ptr(3020~15 0x5588651f18bc in raw 0x5588651f0cf0 len 4024 nref 8),
buffer::ptr(0~1156 0x5588651fa3b0 in raw 0x5588651fa3b0 len 1444 nref 2),
buffer::ptr(3035~4 0x5588651f18cb in raw 0x5588651f0cf0 len 4024 nref 8),
buffer::ptr(1473~2550 0x5588651e8951 in raw 0x5588651e8390 len 4024 nref 7),
buffer::ptr(0~12 0x5588651face0 in raw 0x5588651face0 len 16 nref 2),
buffer::ptr(4023~1 0x5588651e9347 in raw 0x5588651e8390 len 4024 nref 7),
buffer::ptr(0~12 0x5588651fde60 in raw 0x5588651fde60 len 16 nref 2),
buffer::ptr(4020~4 0x5588651fddd4 in raw 0x5588651fce20 len 4024 nref 4),
buffer::ptr(4021~3 0x5588651feed5 in raw 0x5588651fdf20 len 4024 nref 4),
...
```
----
#### A new unittest
* To reproduce the bug, we need to read our good `osdmap` from disk, `decode` it, `encode` a new serialized map, then compress it
* This [testunit](https://github.com/ceph/ceph/pull/33584/commits/1b1c71a2c28c38d3e28f006b1cb164435a653c02) reproduces the corruption bit for bit with real life
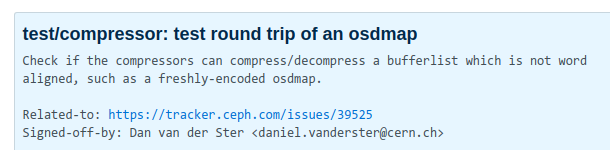
* zlib, snappy, zstd all pass. lz4 fails.
----
* Compressing unaligned memory is complicated:
* The lz4 dev has a nice [blog post](http://fastcompression.blogspot.com/2015/08/accessing-unaligned-memory.html) from 2015 about fast access to unaligned memory
* We [reached out](https://github.com/ceph/ceph/pull/33584) to him on Github
* "Hey, have you seen this kind of corruption before?"
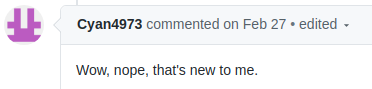
----
* We tried a few different configurations suggested by Cyan4973; nothing changed the corrupting behaviour
* Noticing that a newer lz4 on his dev box didn't corrupt the osdmap, Sage then bisected the commits to find the fix:
[`lz4: af12733 fixed frametest error`](https://github.com/lz4/lz4/commit/af127334670a5e7b710bbd6adb71aa7c3ef0cd72)
```
This fix is applicable to requesting LZ4 to build from data scattered in memory.
Consolidating input as a single contiguous buffer is bound to improve the situation.
-- @Cyan4973
```
LZ4 v1.8.2 and newer includes this commit
----
* CentOS 7 and Ubuntu 18.04 use v1.7.5 so Ceph needs a workaround
* This PR changes the lz4 plugin to rebuild data buffers with contiguous memory
* [`compressor/lz4: work around bug in liblz4 versions <1.8.2`](https://github.com/ceph/ceph/pull/33584/)
* merged to nautilus and octopus, not yet to mimic
----
#### Comments on the impact of this bug
* The combination of **`osd_compression_mode=aggressive`** and `lz4` is the trigger:
* With **`mode=passive`**, only user data in a pool is compressed
* Client data was not corrupted
* RBD data is written from a contiguous buffer
* We have hundreds of ZFS filesystems on RBD and would have noticed by now if the data was corrupted
* The corruption is anyway incredibly rare:
* Our cluster iterated through hundreds of thousands of `osdmap` epochs before corrupting one
---
### What we learned
* All software, libraries, and services are fallible
* Even though they seem to have worked since forever
* Too much reliability leads to unrealistic dependencies, which can create to a disaster
* With zero major outages in 6 years, hundreds of CERN apps built in a dependency on a single Ceph cluster
* This SRE story resonates: [Global Chubby Planned Outage](https://landing.google.com/sre/sre-book/chapters/service-level-objectives/#xref_risk-management_global-chubby-planned-outage)
* Going forward, we will introduce block storage availability zones
* Aiming for 3 or 4 block storage clusters
---
### Thanks and Credits
* To the Ceph firefighters: Teo Mouratidis and Julien Collet.
* To several colleagues who helped talk through the issue:
* Enrico Bocchi, Roberto Valverde, Jan Iven, Pablo Llopis, Arne Wiebalck, Jan van Eldik, Herve Rousseau, Andreas Peters, and others...
* To the Ceph community who set us on the right path:
* `dirtwash` on IRC who pointed to a related tracker 20 minutes after our outage: https://tracker.ceph.com/issues/39525
* Troy and Erik who have seen this crash before and helped with clues.
* Sage Weil (Ceph) and Yann Collet (LZ4) for their expert input and fixes.
---
# ?
---
{"type":"slide","slideOptions":{"transition":"slide","theme":"cern5"},"slideNumber":true,"title":"2020-06-27 - Ceph Tech Talk","tags":"presentation, ceph tech talk"}