# RAL Tier1 Experiments Liaison Meeting - ATLAS notes
https://codimd.web.cern.ch/s/CgJ-qRt4T
Some important links
- [Sites status board](https://cern.ch/ukcloud-site-status-board),
- [weekly status](https://cern.ch/ukcloud-weekly-site-status)
- [JobAccountDashboardUKCloud](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17#),
- [Open ggus tickets](https://cern.ch/open-ggus-tickets-ngi-uk-atlas)
- [Meeting notes from ATLAS Cloud support weekly meeting](https://codimd.web.cern.ch/dCJGAD6bTcSQSm6PZSLBig?view),
- [Notes from ADC operations daily](https://codimd.web.cern.ch/PS3RRbtySa-7o-CujwbD7Q#)
- [Meeting notes from GridPP operations weekly](https://indico.cern.ch/category/4592/)
- [HammerCloud tests](https://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- [Vende farm vo occupancy](https://vande.gridpp.rl.a.uk/next/d/XG5tyqMGz/batch-system-2b-efficiency-plot?orgId=1&refresh=1m&viewPanel=3&from=now-12h&to=now)
- [Internal tickets JIRA]()
# 18 Dec 24
- Ongoing - Ggus ticket Event index jobs failing at RAL -https://ggus.eu/index.php?mode=ticket_info&ticket_id=169427
- Investigate recurring job removal issue due to outdated time exceeded https://stfc.atlassian.net/browse/GSTSM-280
- Slack link - https://scdsystems.slack.com/archives/C051MR0TL4U/p1734322959040199
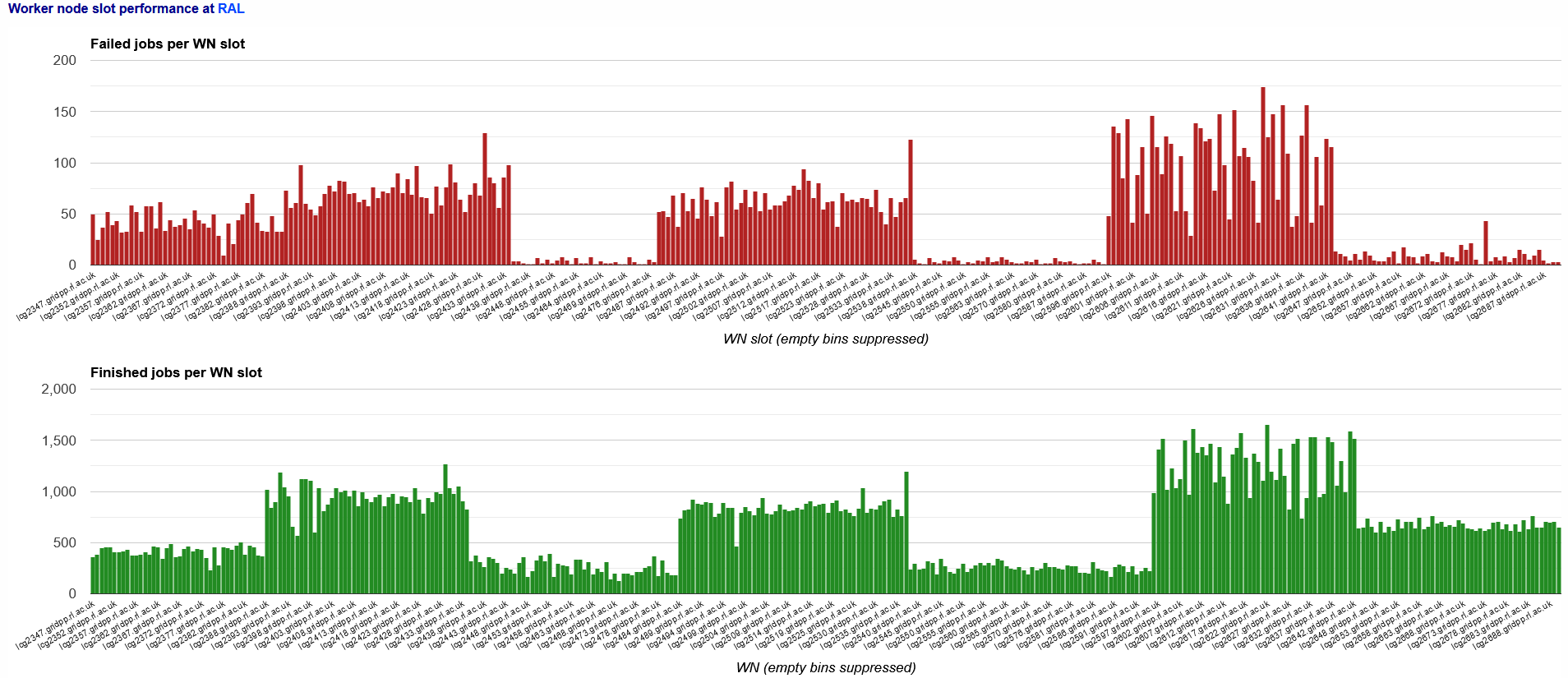
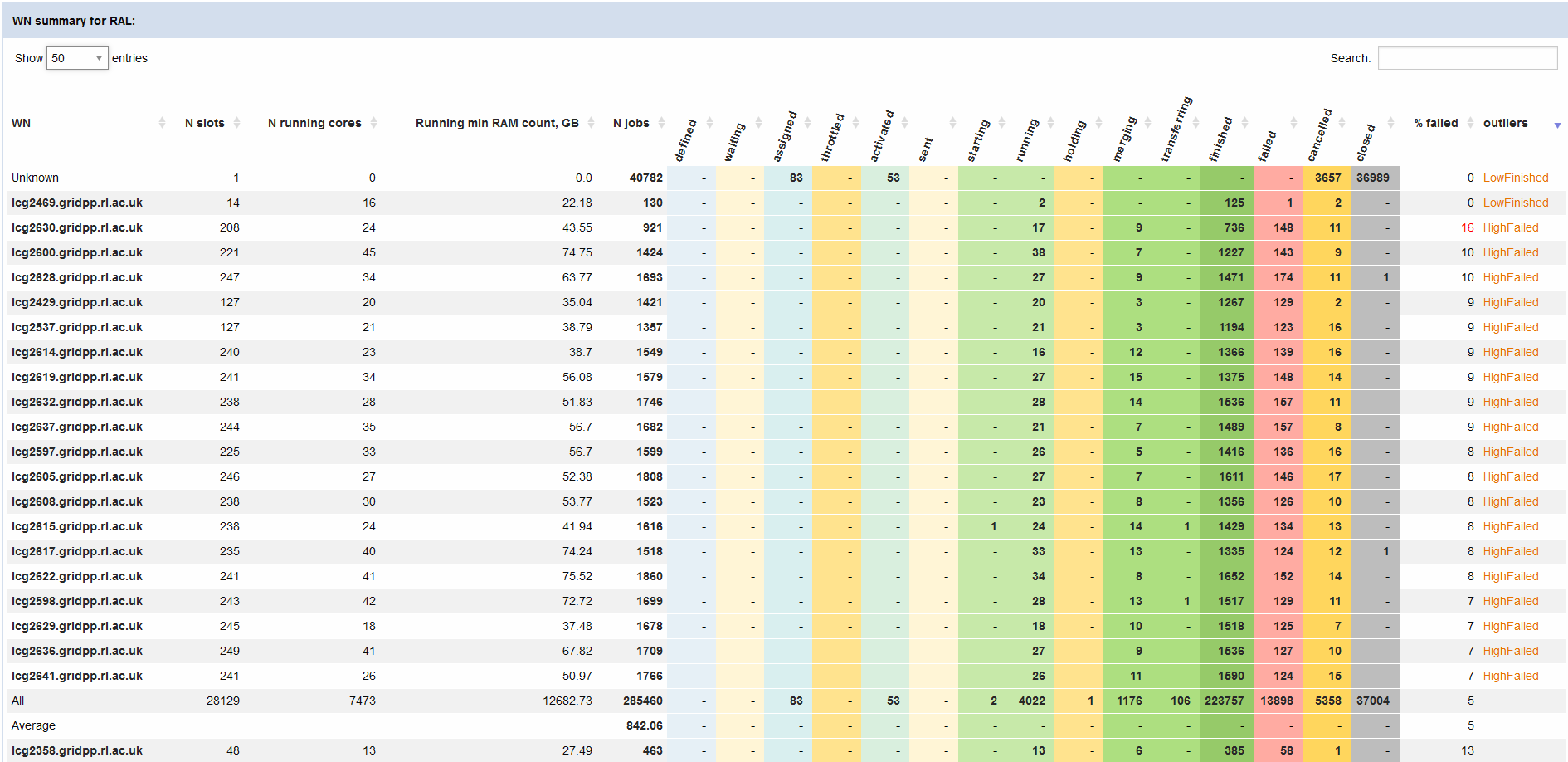
- As a result of the above issues, the efficiency of the jobs is really bad
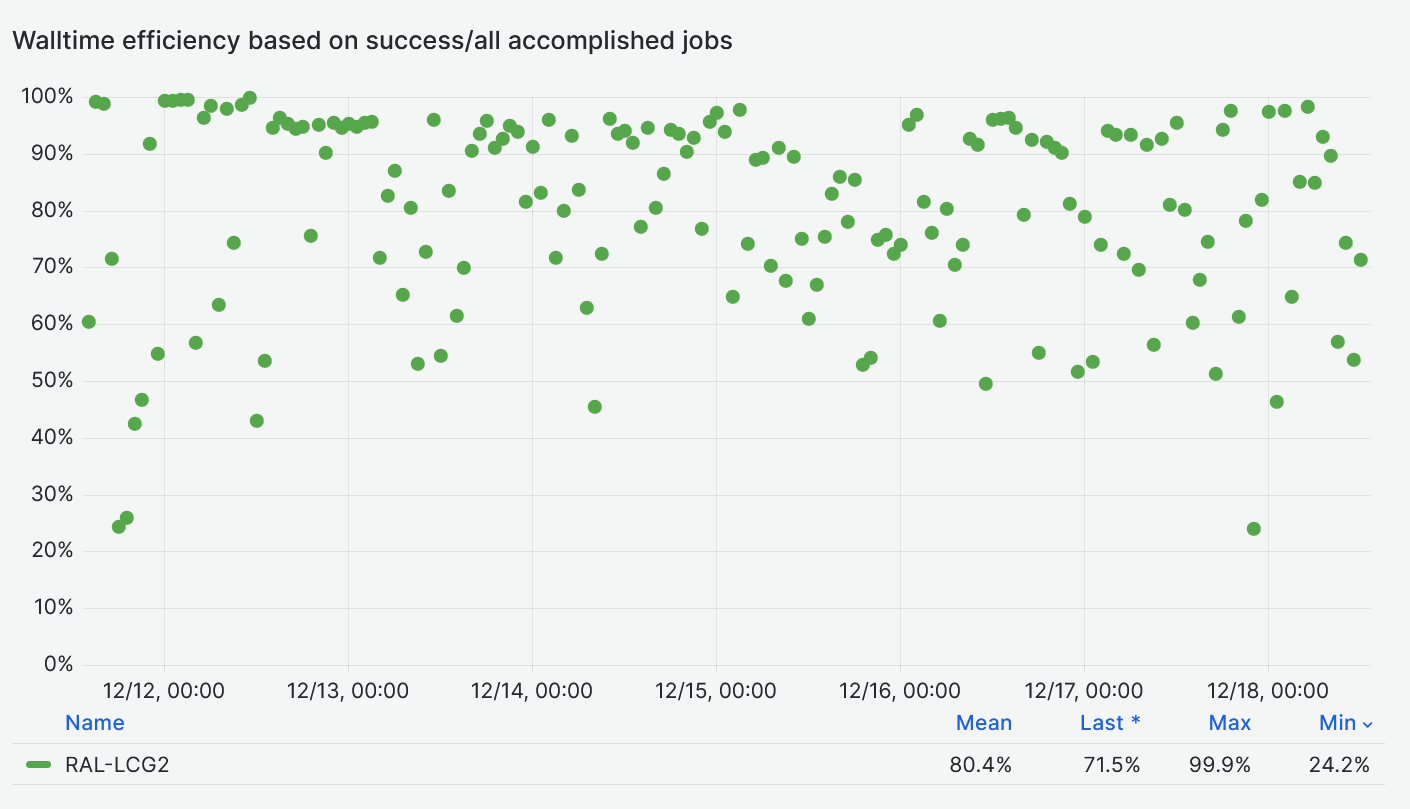
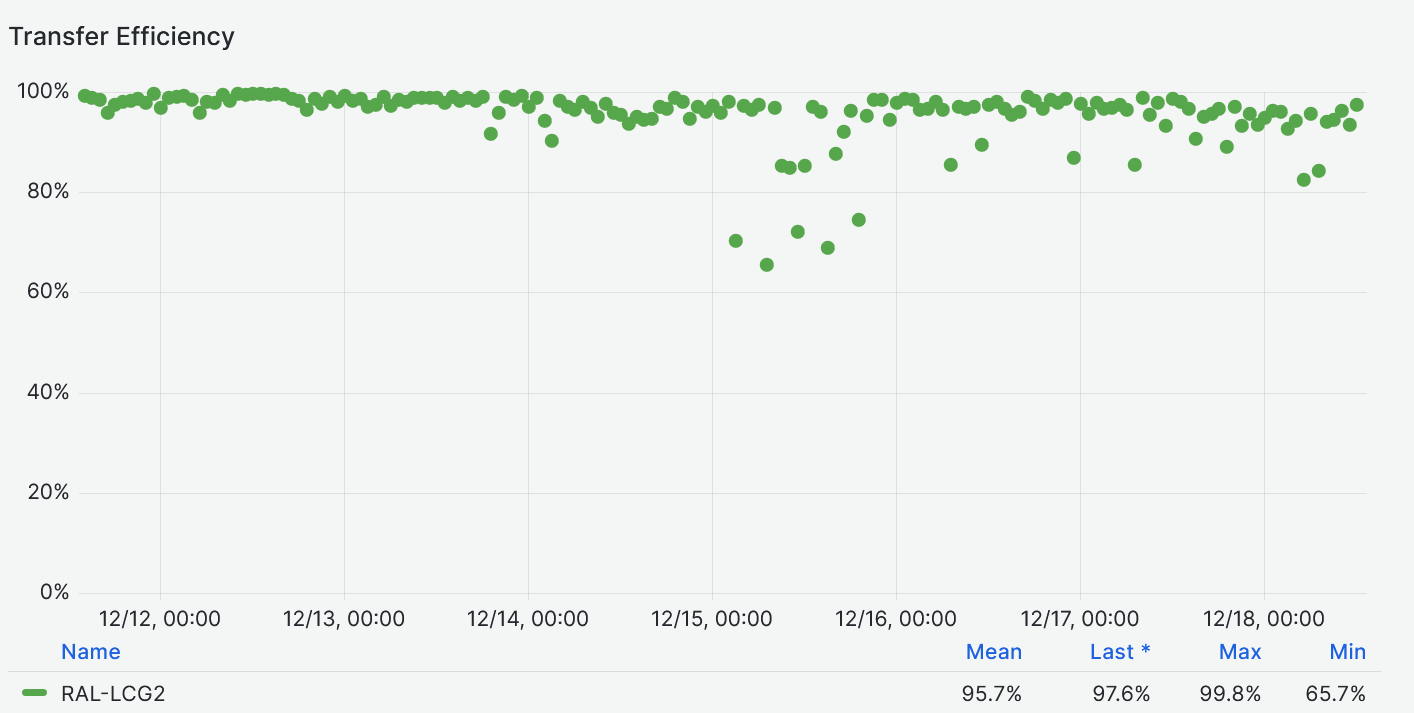
- Transfers effficiency not that bad
- 
- Detailed timeline of the issue if someone would like to know
https://ggus.eu/index.php?mode=ticket_info&ticket_id=169427
- In terms of promptness in responding to this error, here is the timeline of the issue
- 1 - Job failure happens at - 2024-12-13 01:38:37 ( I don't know the time zone of this timestamp)
- 2 - Santi wrote an email to ATLAS cloud support at Dec, 13, 2024 7:58 AM (London time)
- 3 - Brij replied to Santi's email at Dec 13, 2024, 8:26 AM (London time)
- 4 - Brij investigated the issue and found problem with storage in accessing these files, so he wrote to data-services channel at 8:33 AM. ((London time)
- 5 - Brij and Jyotish investigated the issue in from data services till 12:15 PM on friday.
- 6 - Brij wrote in data services with some more error info on Monday at 8:25 AM debugging continued
- 7 - Meanwhile, Santi sent a mail reminder on Sunday 15th at 9:32 AM
- 8 - Brij replied to Santi's email on Monday 16th at 9:00 AM
- 9 - Email conversation continued, Jyotish identified a potential problem and applied a fix which led to improvement of job success rates, kept under observation .
- 10 - New failures reported, based on fresh inputs, a ggus ticket is created - https://ggus.eu/index.php?mode=ticket_info&ticket_id=169427
# 11 Dec 24
- UK Mini-DC ATLAS traffic plot [link](https://monit-grafana.cern.ch/d/FtSFfwdmk/ddm-transfers?orgId=17&from=1733137200000&to=1733191199000&var-binning=10m&var-groupby=src_experiment_site&var-activity=Data%20Challenge&var-protocol=All&var-src_tier=All&var-src_country=All&var-src_cloud=All&var-src_endpoint=All&var-src_token=All&var-columns=src_cloud&var-dst_tier=All&var-dst_country=All&var-dst_cloud=All&var-dst_site=All&var-dst_endpoint=All&var-dst_token=All&var-rows=dst_endpoint&var-measurement=ddm_transfer&var-retention_policy=raw&var-include=&var-exclude=none&var-exclude_es=All&var-include_es_dst=All&var-include_es_src=All&var-activity_disabled=Analysis%20Input&var-activity_disabled=Data%20Consolidation&var-activity_disabled=Deletion&var-activity_disabled=Functional%20Test&var-activity_disabled=Production%20Input&var-activity_disabled=Production%20Output&var-activity_disabled=Staging&var-activity_disabled=User%20Subscriptions&var-src_site=All&var-remote_access=All&var-enr_filters=data.purged_reason%7C%21%3D%7CJob%20canceled%20by%20the%20user&viewPanel=123)
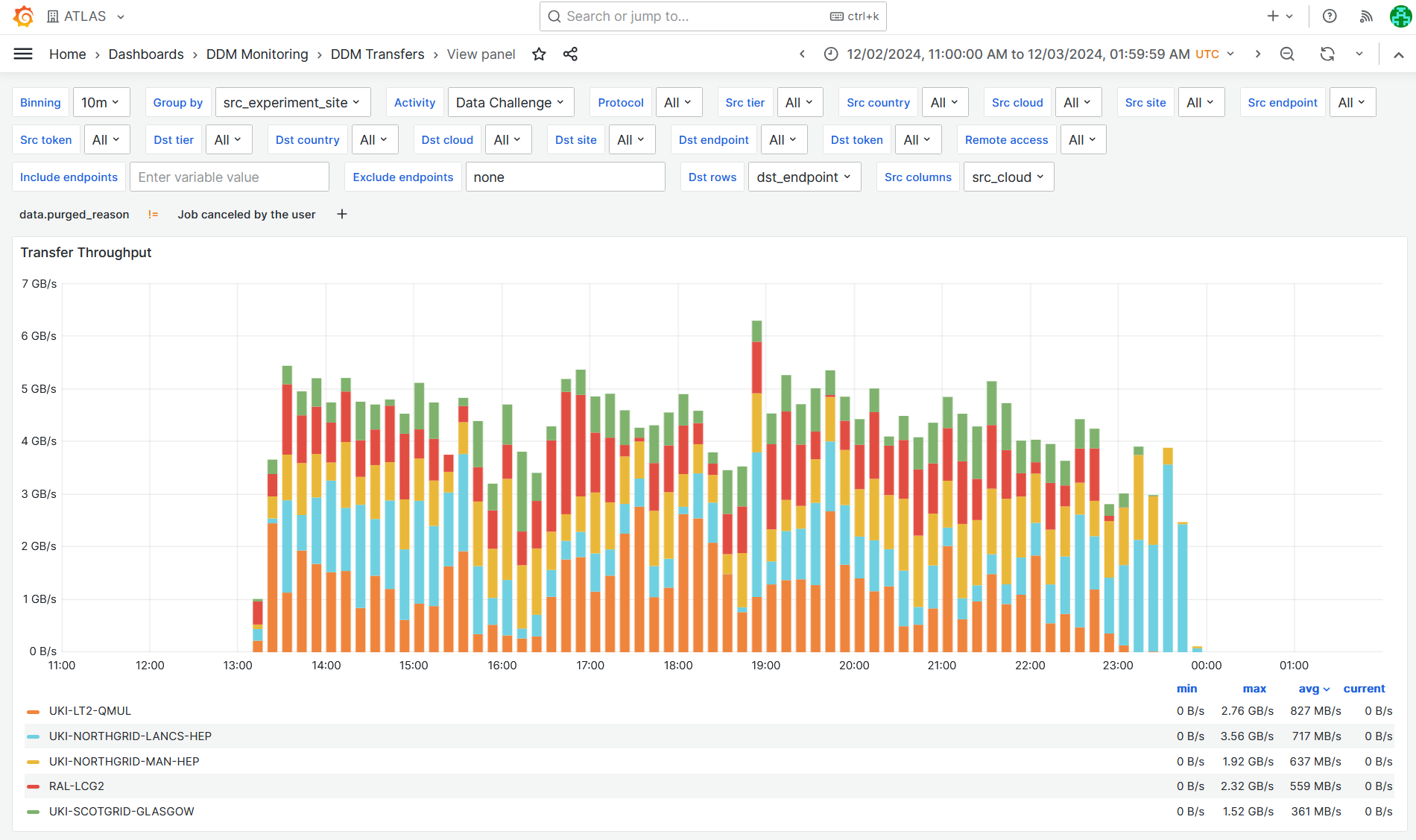
- GGUS ticket about transfer failures from Datatape to echo - [link](https://ggus.eu/index.php?mode=ticket_info&ticket_id=169360)
- Thanks for the swift replies and help from Brian and Jyotish
- Turns out it was a single corrupted file at RAL (and one at CERN) which has been invalidated
- Enabling tokens for ATLAS - [Ticket](https://stfc.atlassian.net/browse/GS-375) (Thanks Tom)
- All CEs passed tests and moved to production on 6th Dec.
- So far all looks normal.
- A Jira task to document and follow-up on the activities underway for improving the ATLAS fair-share in T1 farm [Ticket](https://stfc.atlassian.net/jira/servicedesk/projects/GSTSM/queues/custom/553/GSTSM-258)
- During last 6 months the ATLAS occupancy as percentage of fair share is below other VOs
- Similar behavior seen in all the other multi-VO sites, inclding T1s such as KIT
- Some features of new condor (v24) expected to improve this and wil be tried out.
- WLCG A/R at [100%](https://monit-grafana.cern.ch/goto/H3smMB7Hg?orgId=17)
- CPU slot occupancy average (HS23) vs pledge during last two weeks at [92%](https://monit-grafana.cern.ch/goto/K4JeajVHR?orgId=17), slight improvement from last week.
- Much lower in terms of T1 fair share.
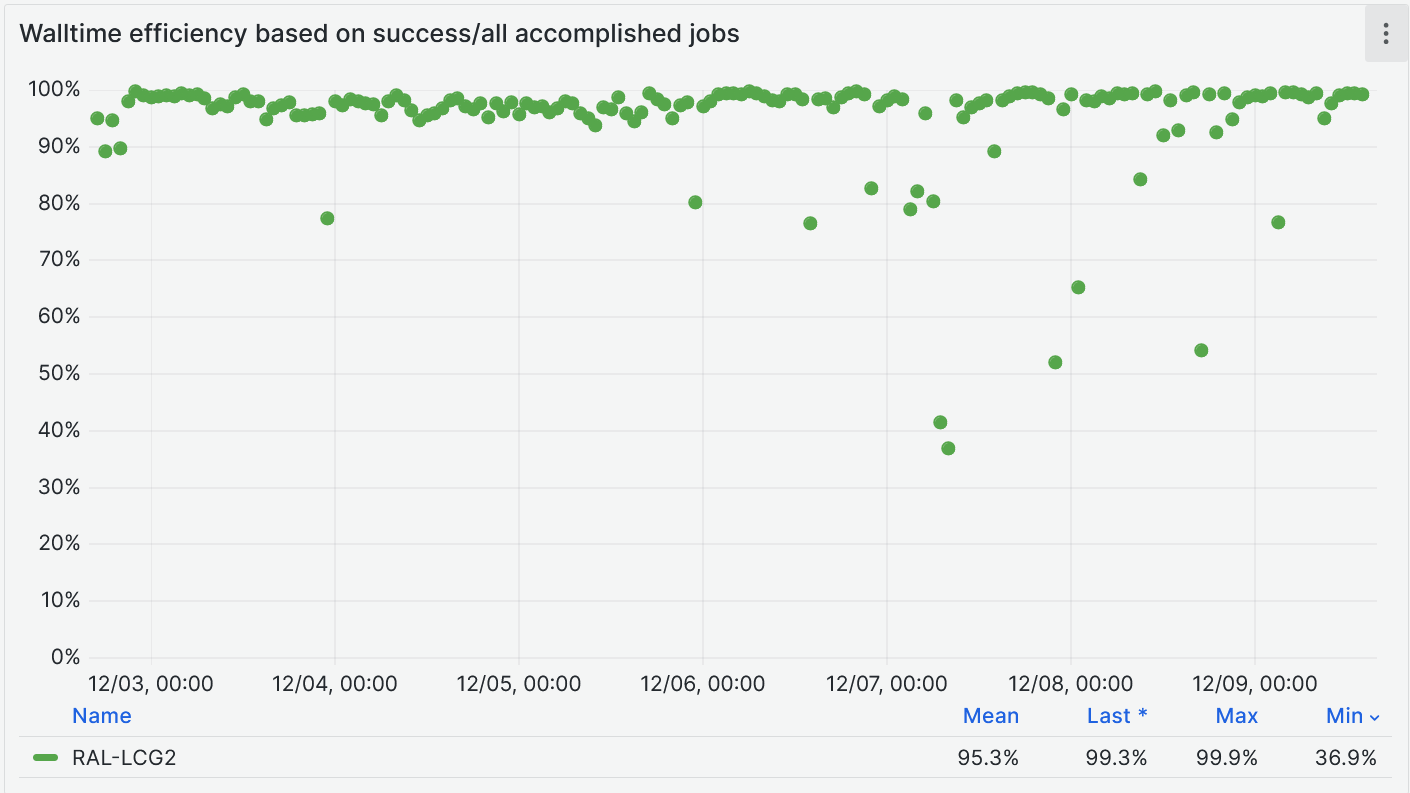
- Walltime efficiency based on success/all accomplished jobs at [95%](https://monit-grafana.cern.ch/goto/iDEw-C4Hg?orgId=17)
- 
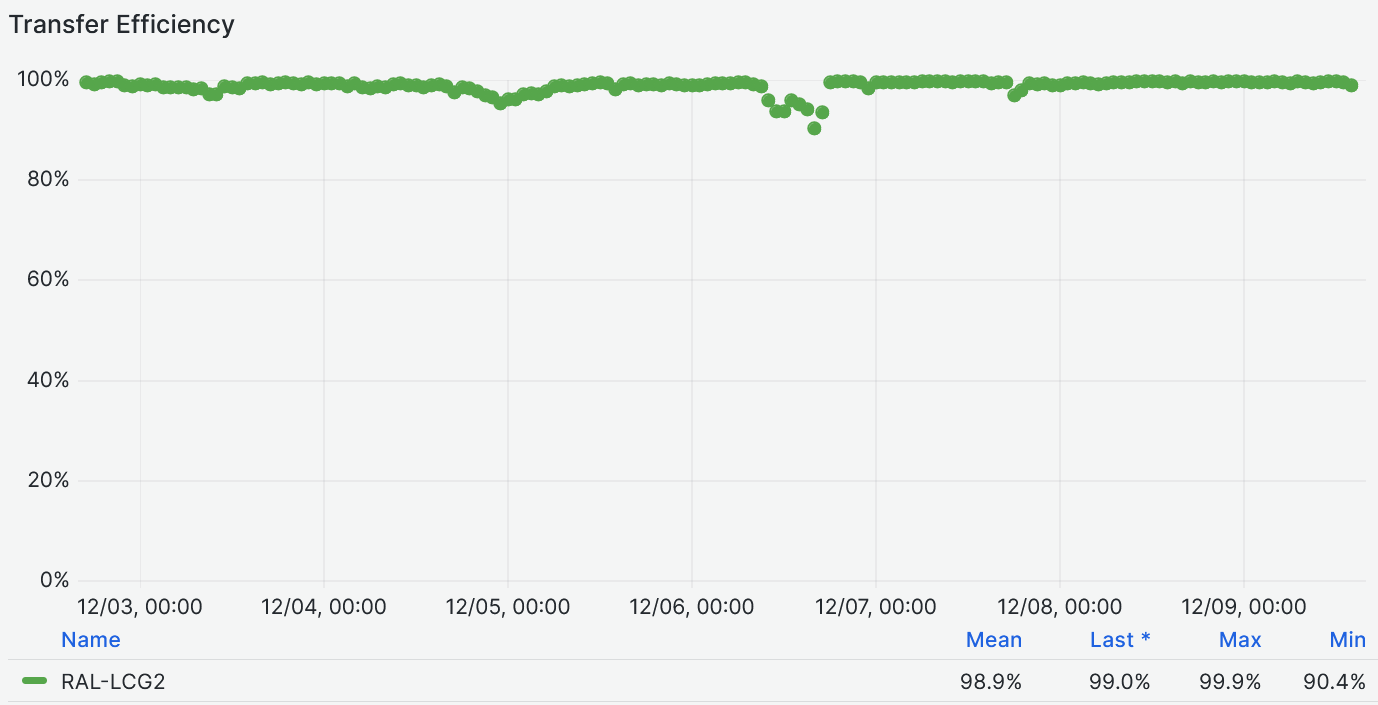
- Data Transfers efficiency at - [99%](https://monit-grafana.cern.ch/goto/iDEw-C4Hg?orgId=17)
- 
- Hammercloud: all green [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
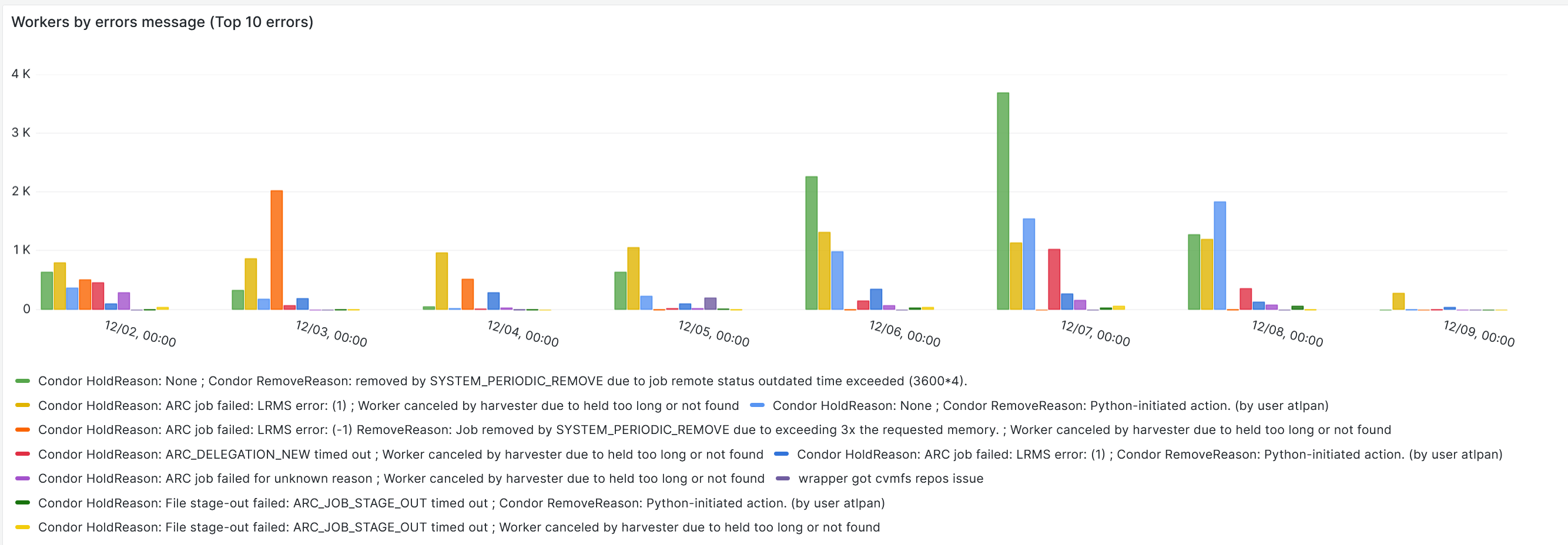
- Spike in job failues on last friday and weekend.
- 
# 04 Dec 24
### General news
- Enabling tokens for ATLAS CEs - [Ticket](https://stfc.atlassian.net/browse/GS-375)
- First test CE passing the [test](https://testbed.farm.particle.cz/cgi-bin/arc.cgi?host=arc-ce-test02.gridpp.rl.ac.uk&port=443&aud=https%3A%2F%2Farc-ce-test02.gridpp.rl.ac.uk&submit=submit)
- We (ATLAS-UK-Cloud) have been asked to present at the ATLAS S&C week, site jumborie session, we are planning contributions and talks, if you have any ideas, please let me know.
- ATLAS UK Mini DC [status](https://monit-grafana.cern.ch/d/FtSFfwdmk/ddm-transfers?orgId=17&from=1733145480000&to=1733177880000&var-binning=10m&var-groupby=src_experiment_site&var-activity=Analysis%20Input&var-activity=Data%20Challenge&var-activity=Data%20Consolidation&var-activity=Data%20rebalancing&var-activity=Express&var-activity=Functional%20Test&var-activity=Production%20Input&var-activity=Production%20Output&var-activity=Recovery&var-activity=SFO%20to%20EOS%20export&var-activity=Staging&var-activity=T0%20Export&var-activity=T0%20Tape&var-activity=User%20Subscriptions&var-activity=default&var-protocol=All&var-src_tier=All&var-src_country=All&var-src_cloud=All&var-src_endpoint=All&var-src_token=All&var-columns=src_cloud&var-dst_tier=All&var-dst_country=All&var-dst_cloud=All&var-dst_site=UKI-SOUTHGRID-RALPP&var-dst_endpoint=All&var-dst_token=All&var-rows=dst_endpoint&var-measurement=ddm_transfer&var-retention_policy=raw&var-include=&var-exclude=none&var-exclude_es=All&var-include_es_dst=All&var-include_es_src=All&var-activity_disabled=Analysis%20Input&var-activity_disabled=Data%20Consolidation&var-activity_disabled=Deletion&var-activity_disabled=Functional%20Test&var-activity_disabled=Production%20Input&var-activity_disabled=Production%20Output&var-activity_disabled=Staging&var-activity_disabled=User%20Subscriptions&var-src_site=All&var-remote_access=All&var-enr_filters=data.purged_reason%7C%21%3D%7CJob%20canceled%20by%20the%20user&viewPanel=123)
### RAL-LCG2
- CPU slot occupancy average [HS23] vs pledge during last week at [86%](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17&from=1732708962997&to=1733313762997)
- 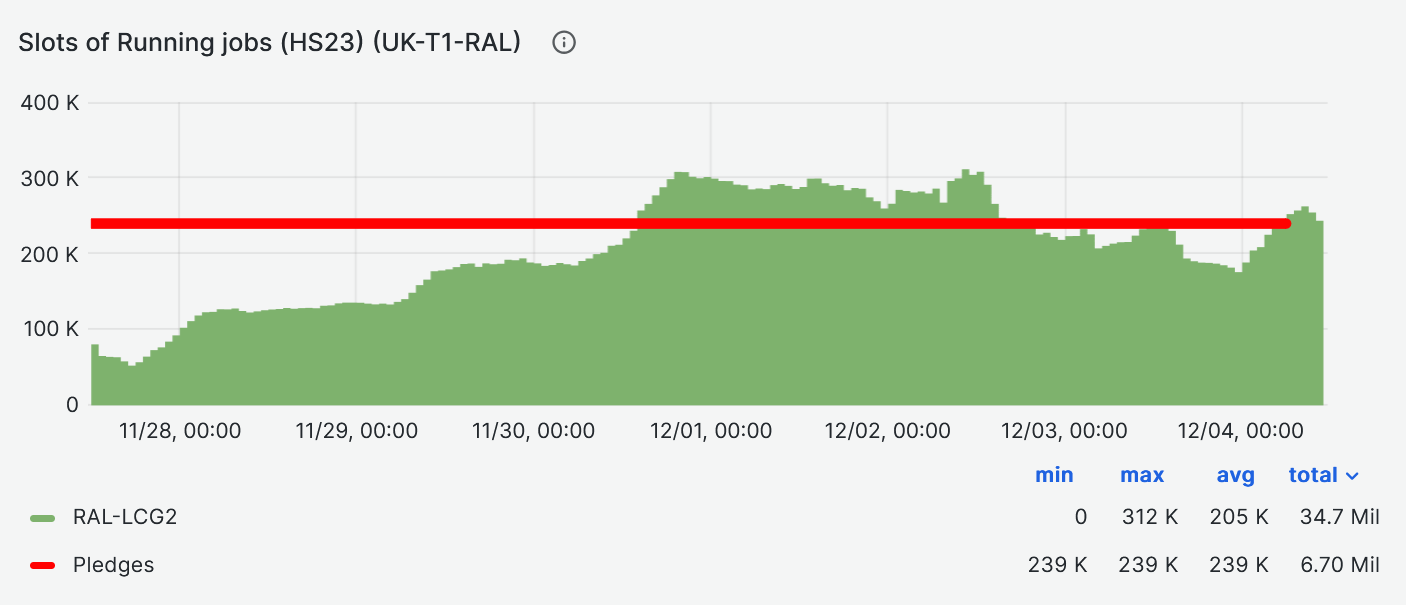
- In the begenning of weak, occpancy down due to network issue on monday
- It took almost 3 days to come back to full occupancy, this is a problem and needs investigation from ATLAS side, working closely with T1 batch farm team.
- Walltime efficiency based on success/all accomplished jobs at [96%](https://monit-grafana.cern.ch/d/D26vElGGz/site-oriented-dashboard?orgId=17&from=1732709125471&to=1733313925472&var-bin=1h&var-groupby_jobs=dst_experiment_site&var-groupby_ddm=dst_experiment_site&var-cloud=UK&var-country=All&var-federation=All&var-site=RAL-LCG2&var-computingsite=All&var-es_division_factor=1&var-measurement=ddm_transfer_1h&var-jobtype=All)
- Data Transfers efficiency at - [98%](https://monit-grafana.cern.ch/d/D26vElGGz/site-oriented-dashboard?orgId=17&from=1732709125471&to=1733313925472&var-bin=1h&var-groupby_jobs=dst_experiment_site&var-groupby_ddm=dst_experiment_site&var-cloud=UK&var-country=All&var-federation=All&var-site=RAL-LCG2&var-computingsite=All&var-es_division_factor=1&var-measurement=ddm_transfer_1h&var-jobtype=All)
- Hammercloud:all clear [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
# 27 Nov 24
### General news
- Enabling tokens for ATLAS - [Ticket](https://stfc.atlassian.net/browse/GS-375)
- First test CE passing the [test](https://testbed.farm.particle.cz/cgi-bin/arc.cgi?host=arc-ce-test02.gridpp.rl.ac.uk&port=443&aud=https%3A%2F%2Farc-ce-test02.gridpp.rl.ac.uk&submit=submit)
- Brief rucio outage on Monday evening causing site queues being blacklisted caused by problems of the Kubernetes infrastructure behind Rucio
- Echo write failures from Oxford reported during last week, cause being investigated.
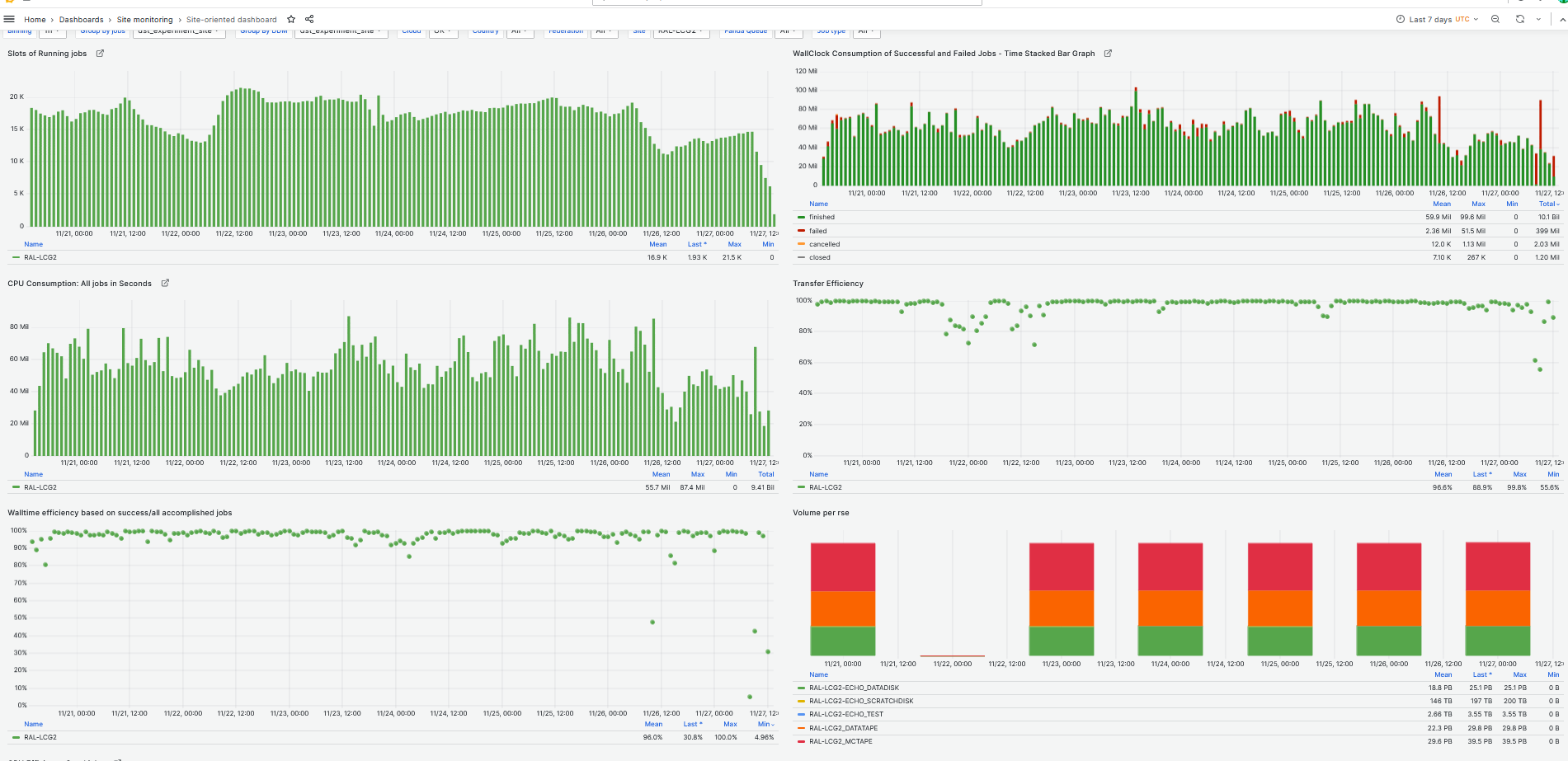
### RAL-LCG2
- CPU slot occupancy average [HS23] vs pledge during last week at [90%](https://monit-grafana.cern.ch/d/D26vElGGz/site-oriented-dashboard?orgId=17&from=1732108985764&to=1732713785764&var-bin=1h&var-groupby_jobs=dst_experiment_site&var-groupby_ddm=dst_experiment_site&var-cloud=UK&var-country=All&var-federation=All&var-site=RAL-LCG2&var-computingsite=All&var-es_division_factor=1&var-measurement=ddm_transfer_1h&var-jobtype=All)
- Walltime efficiency based on success/all accomplished jobs at [96%](https://monit-grafana.cern.ch/d/D26vElGGz/site-oriented-dashboard?orgId=17&from=1732108985764&to=1732713785764&var-bin=1h&var-groupby_jobs=dst_experiment_site&var-groupby_ddm=dst_experiment_site&var-cloud=UK&var-country=All&var-federation=All&var-site=RAL-LCG2&var-computingsite=All&var-es_division_factor=1&var-measurement=ddm_transfer_1h&var-jobtype=All)
- Data Transfers efficiency at - [97%](https://monit-grafana.cern.ch/d/D26vElGGz/site-oriented-dashboard?orgId=17&from=1732108985764&to=1732713785764&var-bin=1h&var-groupby_jobs=dst_experiment_site&var-groupby_ddm=dst_experiment_site&var-cloud=UK&var-country=All&var-federation=All&var-site=RAL-LCG2&var-computingsite=All&var-es_division_factor=1&var-measurement=ddm_transfer_1h&var-jobtype=All)
- Hammercloud:all clear [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
# 20 Nov 24
### General news
- CPU efficiency > 100%:
* Bug in derivation reconstruction v 25.0.19 ([ATEAM-1018](https://its.cern.ch/jira/browse/ATEAM-1018))
* HTCondor 23.10.1 ([Release Notes](https://htcondor.readthedocs.io/en/latest/version-history/feature-versions-23-x.html#version-23-10-1))
* Fixes for artificially high job CPU efficiency.
* Request from WLCG to upgrade.
- From WLCG meeting
* Middleware: On EL8 only if a node took more than ~1 minute to having a working network then fetch-crl has been observed to run exactly once ever at install time and then never again. A 3 year old bug fix has now been back ported to the EPEL EL8 package.
- Dashboards empty during the weekend ([RQF2921444](https://cern.service-now.com/service-portal?id=ticket&table=u_request_fulfillment&n=RQF2921444))
* Kafka outage
- [WLCG weekly report](https://twiki.cern.ch/twiki/bin/view/AtlasComputing/ADCOperationsWeeklySummaries2024)
* brief rucio outage on Thursday causing site queues being blacklisted
*
### RAL-LCG2
- CPU slot occupancy average [HS23] vs pledge during last week at [107%](https://monit-grafana.cern.ch/goto/vBpmbI7Hg?orgId=17)
- Walltime efficiency based on success/all accomplished jobs at [97%](https://monit-grafana.cern.ch/goto/y93CaInHg?orgId=17)
- Data Transfers efficiency at - [96%](https://monit-grafana.cern.ch/goto/y93CaInHg?orgId=17)
- Hammercloud: [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- Single failure on 14th with stage-in error [link](https://bigpanda.cern.ch/jobs/?pandaid=6404239080,6404239717&mode=nodrop)
- ` ddm, 100: setupper.setup_source() could not get VUID of prodDBlock with An unknown exception occurred. Details: no error information passed (http status code: 404) Traceback (most recent call last): File "/opt/panda/lib/python3.11/site-packages/pandaserver/dataservice/ddm.py", line 455, in list_datasets for name in client.list_dids(scope, filters, collection): ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/opt/panda/lib/python3.11/site-packages/rucio/client/didclient.py", line`
- `pilot, 1099: Failed to stage-in file: [ServerConnectionException()]:failed to transfer files using copytools=['rucio']`
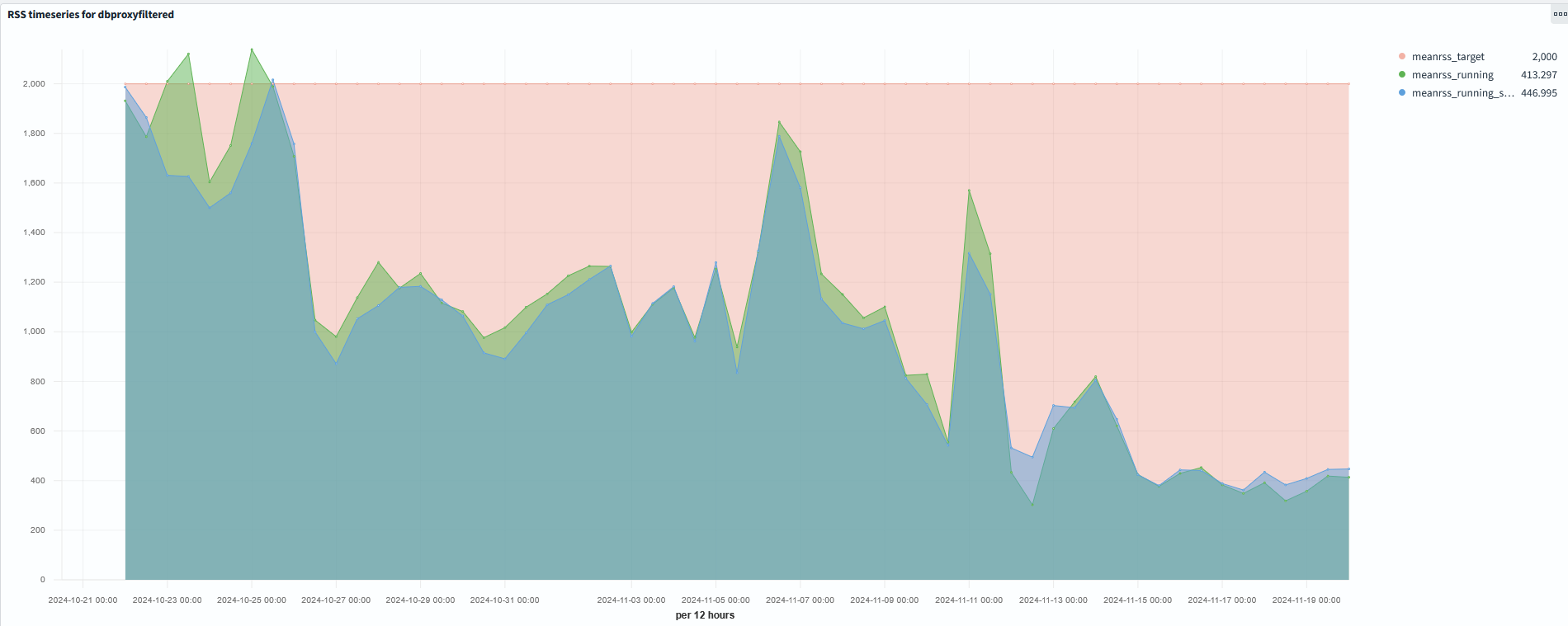
- Mean RSS of ATLAS jobs during last month
- 
# 28 Oct 24 - 13 Nov 24
### General news
- GGUS replacement ([WLCG Helpdesk](https://helpdesk.ggus.eu))
* Status presented at WLCG Coordination ([pdf](https://indico.cern.ch/event/1475074/contributions/6211811/attachments/2963169/5212301/WLCG_OPS_Meeting_17.10.24%20Update.pdf)).
* GGUS will be switched to read-only in the end of January due to end of license agreement for underlying software.
- Switching SAM to the new IAM instance. All sites which did not upgrade to lcg-iam-lsc-atlas-1.0.0-1.el9.noarch.rpm (WLCG) or vo-client-lcmaps-voms-136-1.osg23.el9.noarch.rpm (OSG) will start failing WLCG availibility and reliability tests on 13.11.2024.
### RAL-LCG2
- CPU slot occupancy average [HS23] vs pledge during last week at [96%](https://monit-grafana.cern.ch/goto/nIkRIYMNg?orgId=17)
- CPU slot occupancy average (HS23) vs pledge during last two weeks at [84%](https://monit-grafana.cern.ch/goto/ba-LFdZNR?orgId=17)
- 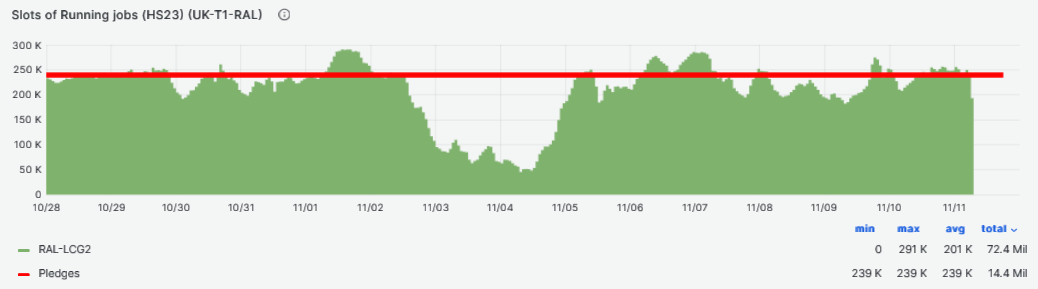
- Dip in occupancy between 03/11 to 05/11
- No obvious reasons from site end.
- Walltime efficiency based on success/all accomplished jobs at [97%](https://monit-grafana.cern.ch/goto/xLTZuoMHR?orgId=17)
- Data Transfers efficiency at - [97.4%](https://monit-grafana.cern.ch/goto/xLTZuoMHR?orgId=17)
- Hammercloud: All clear[Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
# 14 Oct 24 - 27 Oct 24
### General news
- Last quaterly on 16th Oct [report](https://indico.cern.ch/event/1445170/contributions/6083443/attachments/2948068/5183577/Brij-RAL-Tier1-ATLAS-2024Q3.pdf)
- CHEP24 last week, good representation from UK and GridPP
- ADC report from last week [link](https://indico.cern.ch/event/1467453/contributions/6178419/attachments/2952613/5190711/atlas-crc-22October2024.pdf)
### RAL-LCG2
- CPU slot occupancy average (HS23) vs pledge during last week at [80%](https://monit-grafana.cern.ch/goto/ba-LFdZNR?orgId=17)
- Walltime efficiency based on success/all accomplished jobs at [97%](https://monit-grafana.cern.ch/goto/L97JKOZNR?orgId=17)
- Data Transfers efficiency at - [97.4%](https://monit-grafana.cern.ch/goto/L97JKOZNR?orgId=17)
- Hammercloud: All clear[Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
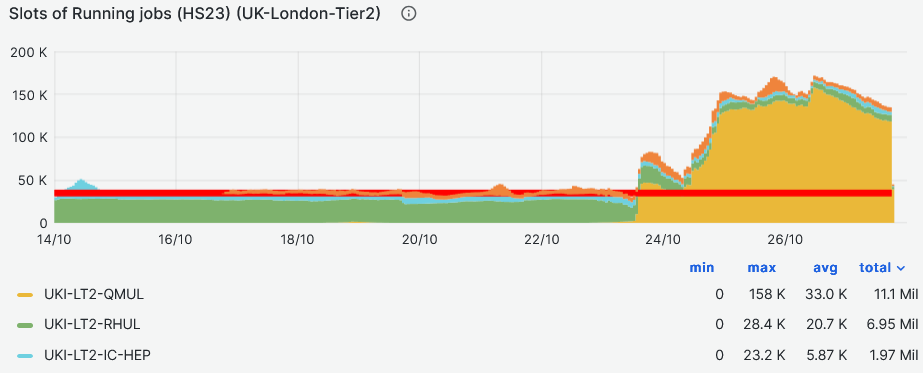
### T2/T3s
- QMUL site back in production
- 
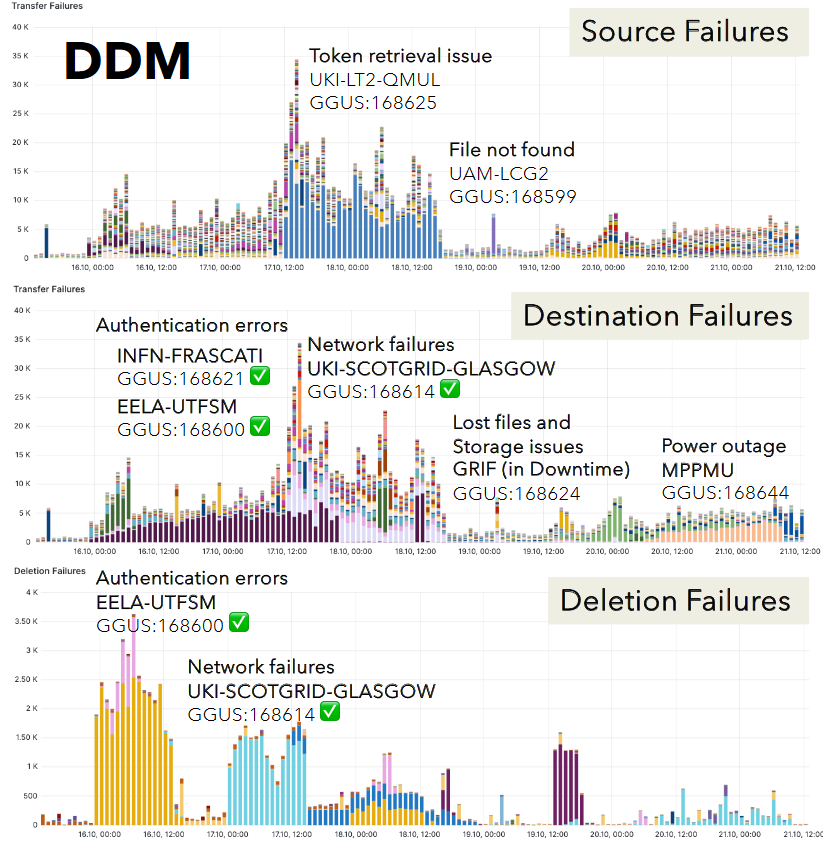
- Operation news from ATLAS ADC
- 
- Few other ggus tickets - List of open tickets [ggus](https://ggus.eu/index.php?mode=ticket_search&show_columns_check%5B0%5D=TICKET_TYPE&show_columns_check%5B1%5D=AFFECTED_VO&show_columns_check%5B2%5D=AFFECTED_SITE&show_columns_check%5B3%5D=PRIORITY&show_columns_check%5B4%5D=RESPONSIBLE_UNIT&show_columns_check%5B5%5D=STATUS&show_columns_check%5B6%5D=DATE_OF_CHANGE&show_columns_check%5B7%5D=SHORT_DESCRIPTION&show_columns_check%5B8%5D=SCOPE&supportunit=NGI_UK&su_hierarchy=0&vo=atlas&specattrib=none&status=open&typeofproblem=all&ticket_category=all&date_type=creation+date&tf_radio=1&timeframe=any&from_date=03+Jul+2019&to_date=04+Jul+2019&orderticketsby=REQUEST_ID&orderhow=desc&search_submit=GO%21)
[Deletions](https://monit-grafana.cern.ch/d/FtSFfwdmk/ddm-transfers?orgId=17&var-binning=$__auto_interval_binning&var-groupby=dst_cloud&var-activity_disabled=Analysis%20Input&var-activity_disabled=Data%20Consolidation&var-activity_disabled=Deletion&var-activity_disabled=Functional%20Test&var-activity_disabled=Production%20Input&var-activity_disabled=Production%20Output&var-activity_disabled=Staging&var-activity_disabled=User%20Subscriptions&var-activity=All&var-protocol=All&var-src_tier=All&var-src_country=All&var-src_cloud=All&var-src_site=All&var-src_endpoint=All&var-src_token=All&var-dst_tier=All&var-dst_country=All&var-dst_cloud=All&var-dst_site=All&var-dst_endpoint=RAL-LCG2_DATATAPE&var-dst_endpoint=RAL-LCG2_MCTAPE&var-dst_token=All&var-remote_access=All&var-include=RAL-LCG2&var-exclude=none&var-exclude_es=All&var-include_es_dst=All&var-include_es_src=All&var-rows=dst_cloud&var-columns=src_cloud&var-measurement=ddm_transfer&var-retention_policy=raw&from=now-30d&to=now)

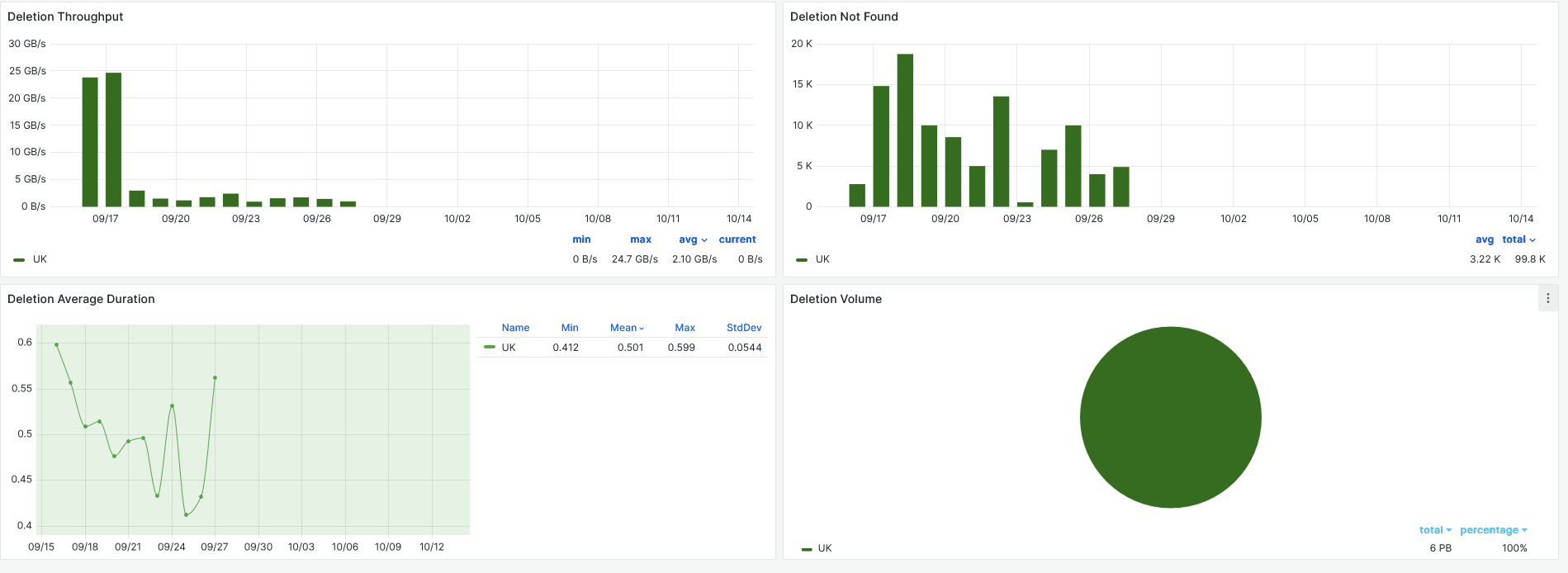
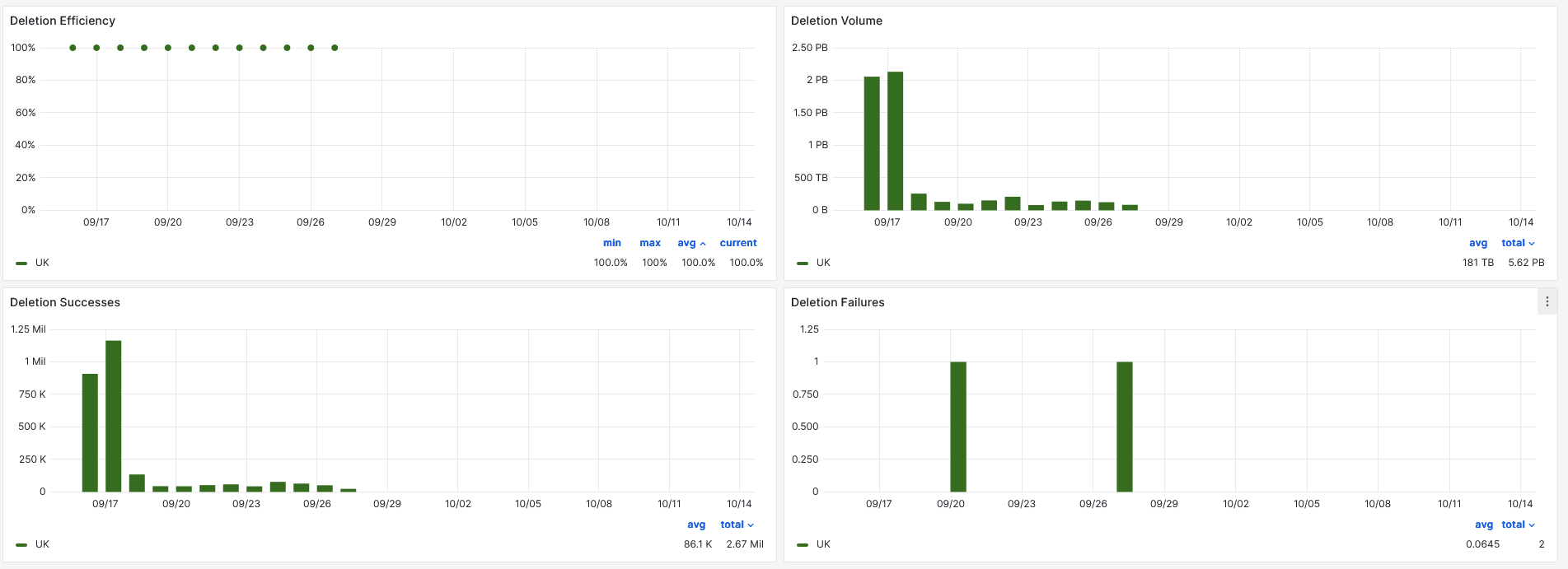
## 09-10-2024
### General news
- Susex new site/CE commisioning finished, running jobs successfully - closed the ticket - https://ggus.eu/index.php?mode=ticket_info&ticket_id=168428
- Ongoing, ATLAS software and computing week - https://indico.cern.ch/event/1454958/
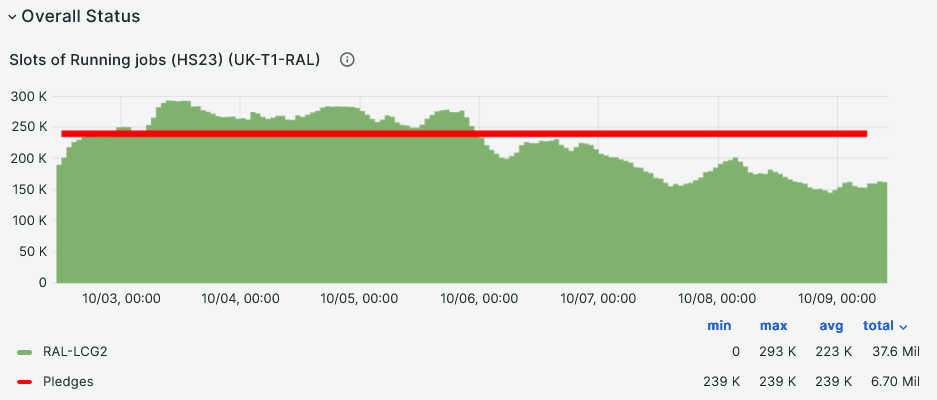
### RAL-LCG2
- CPU slot occupancy average (HS23) vs pledge during last week at [93%](https://monit-grafana.cern.ch/goto/FHg4DXzHR?orgId=17)
- 
- Walltime efficiency based on success/all accomplished jobs at [96.5%](https://monit-grafana.cern.ch/goto/ZX9IvXkNg?orgId=17)
- Data Transfers efficiency at - [98.5%](https://monit-grafana.cern.ch/goto/ZX9IvXkNg?orgId=17)
- Hammercloud: All clear[Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
## 02-10-2024 (Won't be able to connect due to a clash)
### General news
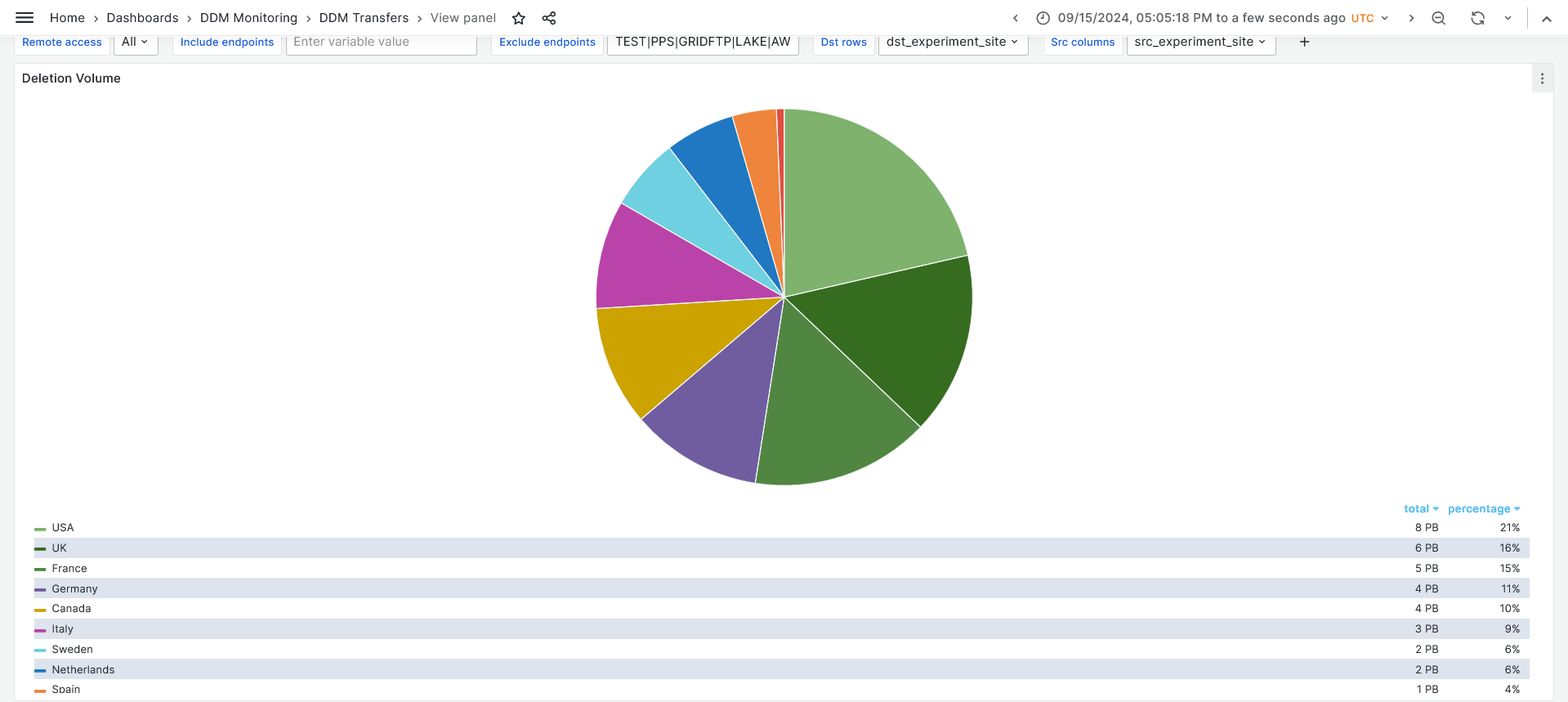
- Deletion campaign, 6 PB deleted from RAL-Tape during last week.
- https://monit-grafana.cern.ch/goto/XiXgKHzNR?orgId=17
- 
### RAL-LCG2
- CPU slot occupancy average (HS23) vs pledge during last week at [106%](https://monit-grafana.cern.ch/goto/iIHHKHkNR?orgId=17)
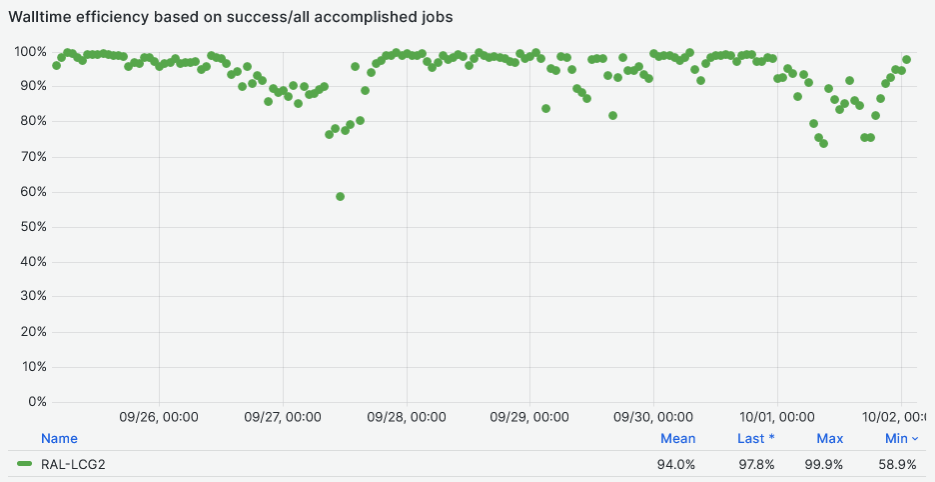
- Walltime efficiency based on success/all accomplished jobs at [94%](https://monit-grafana.cern.ch/goto/cNWvFNzNR?orgId=17)
- Mainly due to overloaded xrootd gateway ?
- most of the errors seen are something like https://bigpanda.cern.ch/jobs/?pandaid=6352856991&mode=nodrop
```
sup, 9000: Diag from worker : Condor HoldReason: File stage-in failed: Transfer of None failed: Failed to open file ; Worker canceled by harvester due to held too long or not found taskbuffer, 300: The worker was cancelled while the job was starting : Condor HoldReason: File stage-in failed: Transfer of None failed: Failed to open file ; Worker canceled by harvester due to held too long or not found
```
- 
- Data Transfers efficiency at - [98%](https://monit-grafana.cern.ch/goto/cNWvFNzNR?orgId=17)
- Hammercloud: All clear[Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- Jira ticket to DDM ops for deletions - https://its.cern.ch/jira/browse/ATLDDMOPS-5713
- RAL-LCG2_TAPE-TEST to be removed from CRIC ?
- Checked with Alessandra, and she says it might be needed for Data challenges.
- update on the ticket by Alessandra "that RSE is the one we used for the post DC24 tests. We will likely need it again in February for miniDCs involving tape. We should keep it."
## 25-09-2024
### General news
- (ATLAS overall) Storage deletions: Application of the Lifetime Model:
- 33 PB on disk; deletions began on Friday
- 11 PB on tape; deletions began Monday
- Additional 24 PB that have been unlocked since the previous deletion campaign
- Completion is expected in two weeks
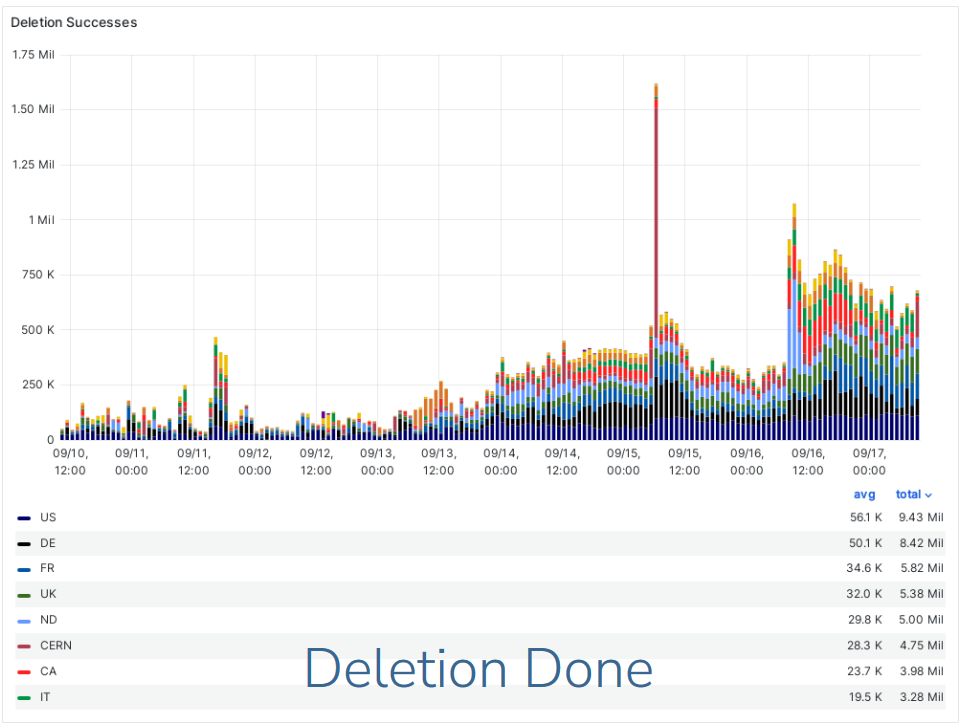
### RAL-LCG2
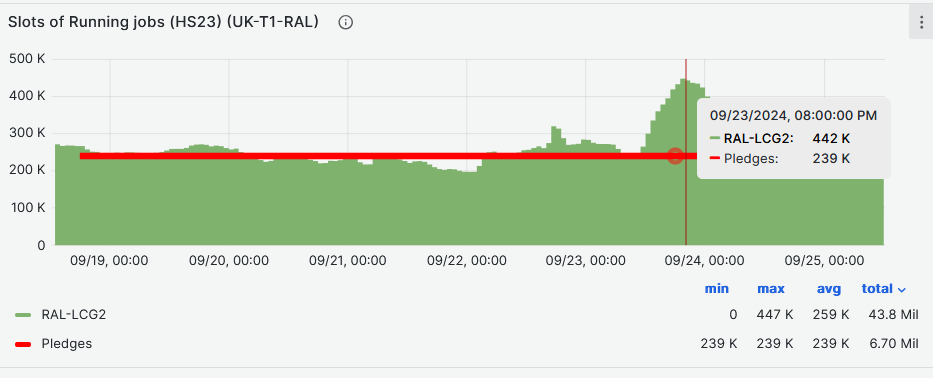
- CPU slot occupancy average (HS23) vs pledge during last week at [108%](https://monit-grafana.cern.ch/goto/8T1SdsRHR?orgId=17)
- 
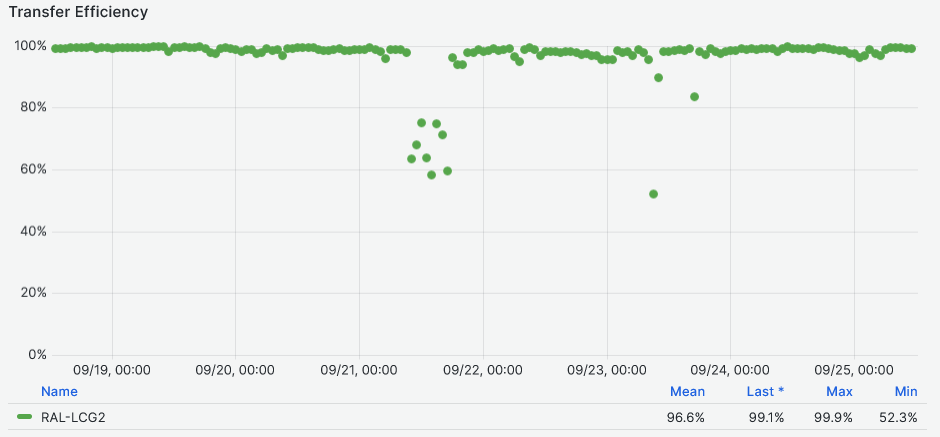
- Walltime efficiency based on success/all accomplished jobs at [97%](https://monit-grafana.cern.ch/goto/EdeSdsRNR?orgId=17)
- Data Transfers efficiency at - [97%](https://monit-grafana.cern.ch/goto/EdeSdsRNR?orgId=17)
- 
- Hammercloud: All clear[Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- Jira ticket to DDM ops for deletions - https://its.cern.ch/jira/browse/ATLDDMOPS-5713
- RAL-LCG2_TAPE-TEST to be removed from CRIC
## 18-09-2024
### RAL-LCG2
- Following the low occupancy of previos week, the jobs slot occupancy increased towards the end of last week. CPU slot occupancy average (HS23) vs pledge during last week at [95%](https://monit-grafana.cern.ch/goto/QRBSinRHg?orgId=17)
- Walltime efficiency based on success/all accomplished jobs at [97%](https://monit-grafana.cern.ch/goto/hxcmue6Ig?orgId=17)
- Data Transfers efficiency at - [97%](https://monit-grafana.cern.ch/goto/hxcmue6Ig?orgId=17)
- Hammercloud: All clear[Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
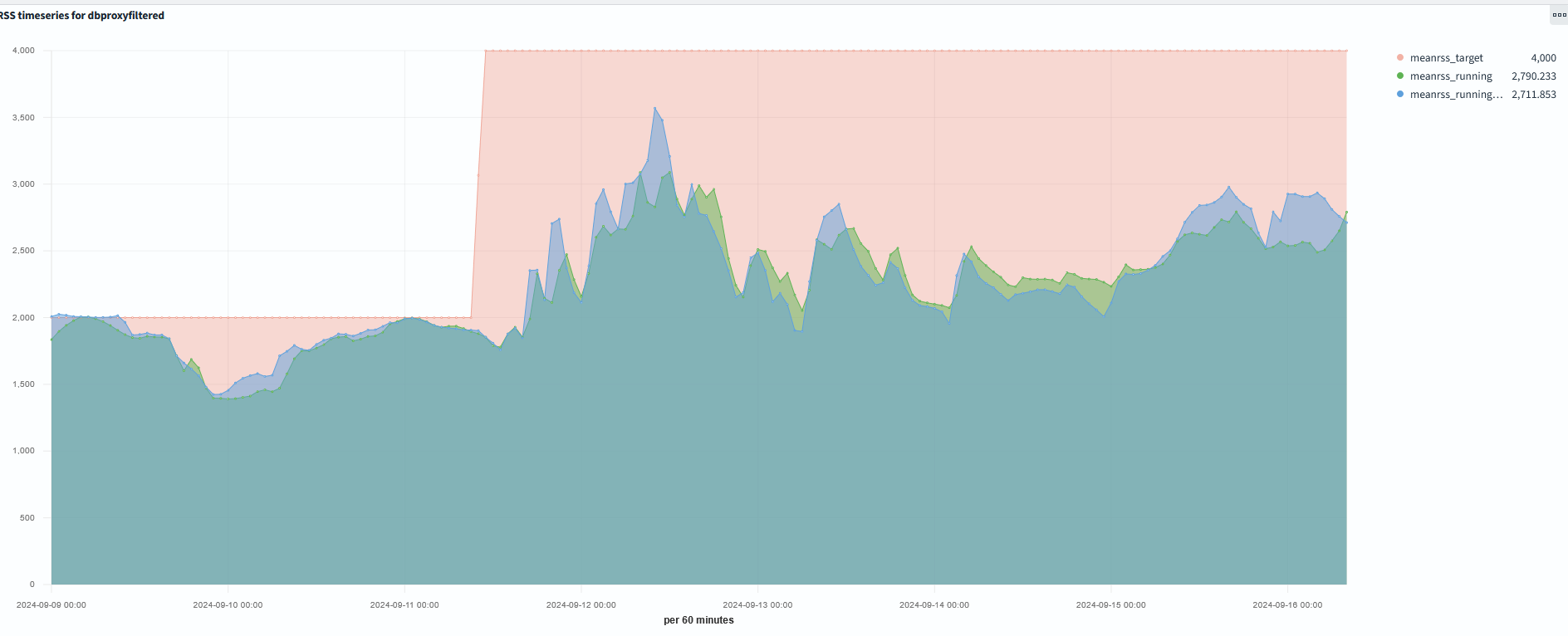
- Following the memory update last week, the mean memory usage of the RAL-LCG2 jobs has increased
- 
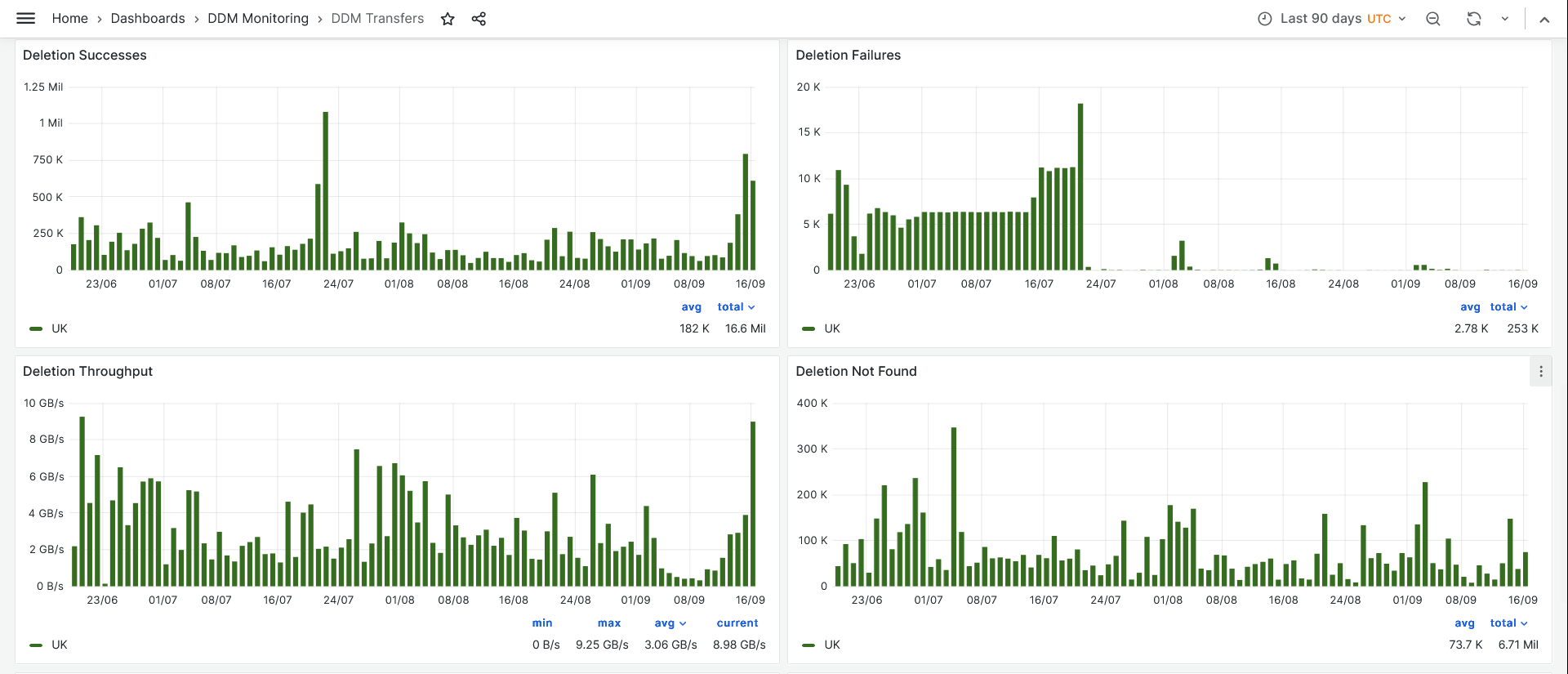
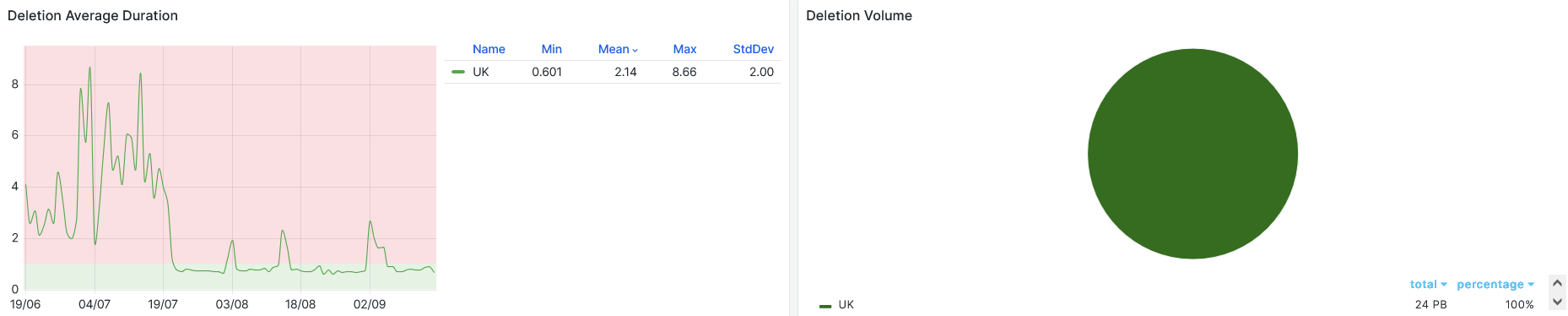
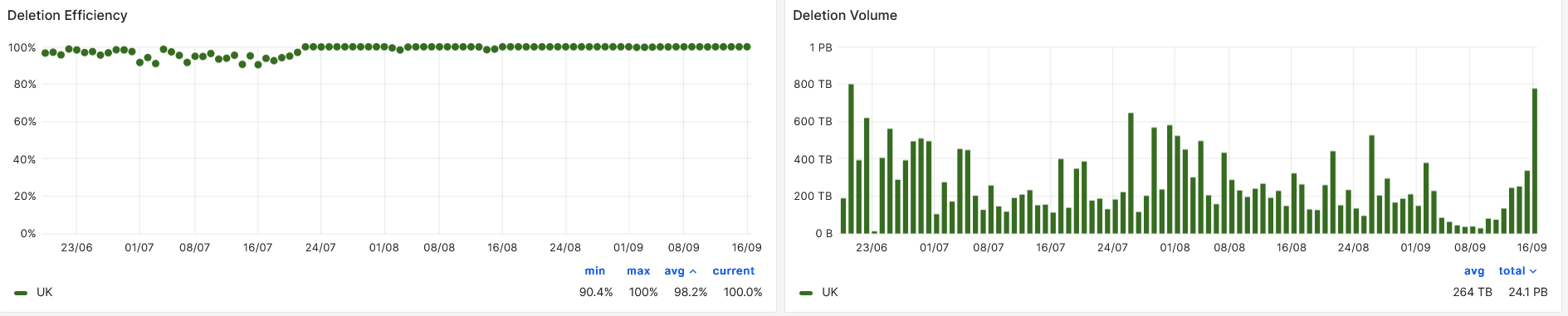
- Deletions , after removing the old endpoint gateway, its as good as anyone
- 
- 
- 
## 11-09-2024
### General news
- Final GDB is going on since 11:30 this morning - https://indico.cern.ch/event/1356138/
- ATLAS worklods low during last week, raised the issue with ADC [Daily ADC ops](https://codimd.web.cern.ch/PS3RRbtySa-7o-CujwbD7Q?view#09092024-Monday)
- Its a general situation due to lack of MC workflows at ATLAS and almost all the sites are getting low job pressure.
- Also raised the issue of uneven job distribution during last week across sites, it can be due to multiple factors but ATLAS ADC needs to work on this.
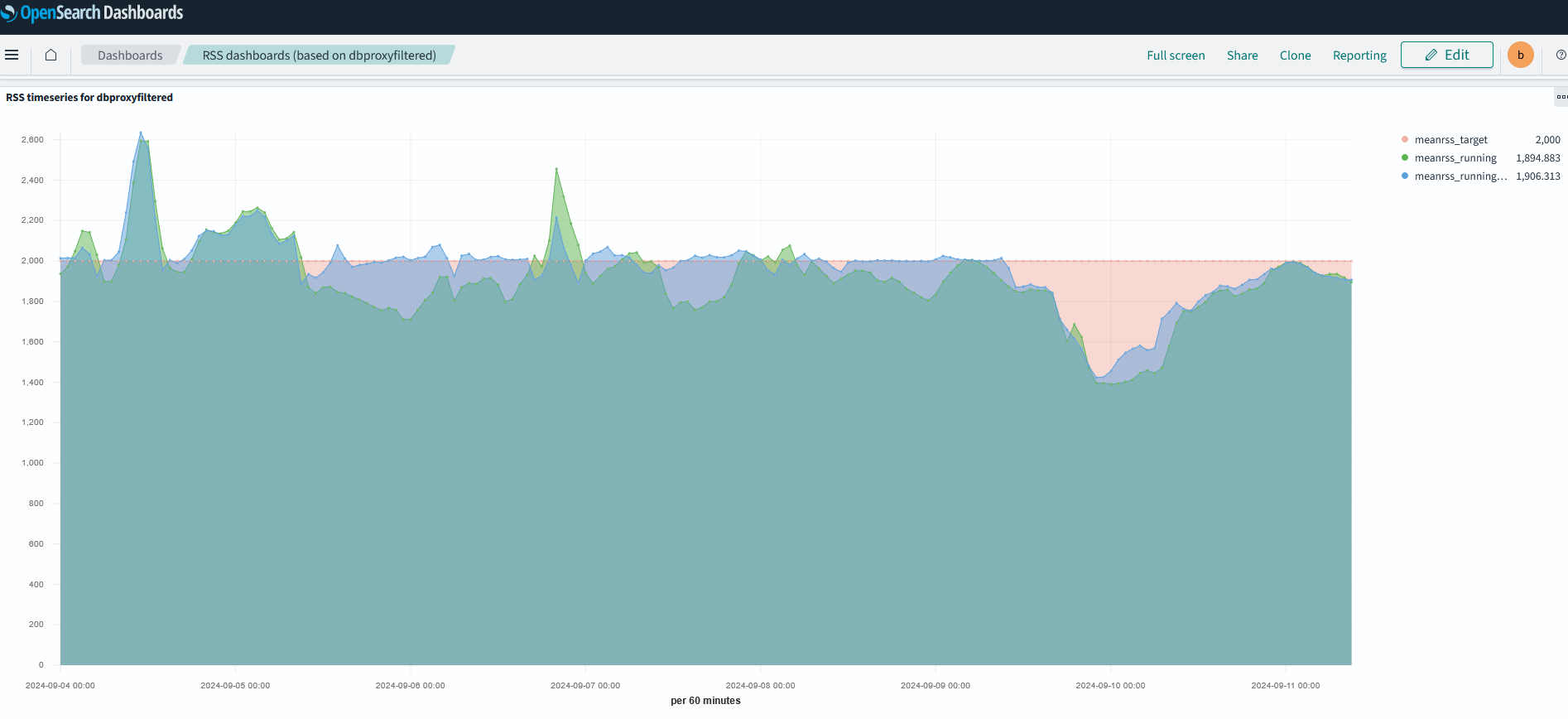
- Following up from last week and after discussions with ADC, updated the MaxRSS (from 3000 to 6000) and MeanRSS (2000 to 4000) values at RAL Panda CRIC
- Setup a [dashboard](https://os-atlas.cern.ch/dashboards/app/dashboards?security_tenant=global#/view/9d64bd00-4a87-11ef-be3c-453f5cb66f0f?_g=(filters%3A!(('%24state'%3A(store%3AglobalState)%2Cmeta%3A(alias%3A!n%2CcontrolledBy%3A'1721913494719'%2Cdisabled%3A!f%2Cindex%3A'620eaaf0-bfac-11ea-b7f2-27bdf2c0b5dc'%2Ckey%3Acomputingsite.keyword%2Cnegate%3A!f%2Cparams%3A(query%3ARAL)%2Ctype%3Aphrase)%2Cquery%3A(match_phrase%3A(computingsite.keyword%3ARAL))))%2CrefreshInterval%3A(pause%3A!t%2Cvalue%3A0)%2Ctime%3A(from%3Anow-7d%2Fd%2Cto%3Anow))) for monitoring the memory utilization. This is the last week's memory usage for RAL.
- 
### RAL-LCG2
- CPU slot occupancy average (HS23) vs pledge during last week at [50%](https://monit-grafana.cern.ch/goto/hrxzn-eSR?orgId=17)
- Walltime efficiency based on success/all accomplished jobs at [98%](https://monit-grafana.cern.ch/goto/hrxzn-eSR?orgId=17)
- Data Transfers efficiency at - [98%](https://monit-grafana.cern.ch/goto/hrxzn-eSR?orgId=17)
- Hammercloud: All clear[Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- No ATLAS VO specific ticket in the system.
## 04-09-2024
### General news
- No incedent during last two weeks, stable operations and good resource delivery.
- Need to update CRIC for MaxRSS and MinRSS, ATLAS has requested this. - Details in the presentation here - https://cernbox.cern.ch/s/trDVDlmkjVYgHcU
- Mainly to better use the available memory by refactoring the jobs according to the memory.
- Update MaxRSS to 6 GB/core and MeanRSS to 4 GB/core
- ATLAS has asked us to update this, if there is no problem with this from the Batch system team side, then i can make the changes in CRIC. please confirm.
- Reported, 1 file checksum failure and missing 1 file in the echo datadisk
- Recalled from Tape and restored, thanks a lot for the help from George and data services team.
### RAL-LCG2
- CPU HS23 resource delivery above pledge at 105%
- Network transfers - 98.6%
- Job efficiency - 98%
- Nothing pending on the tickets
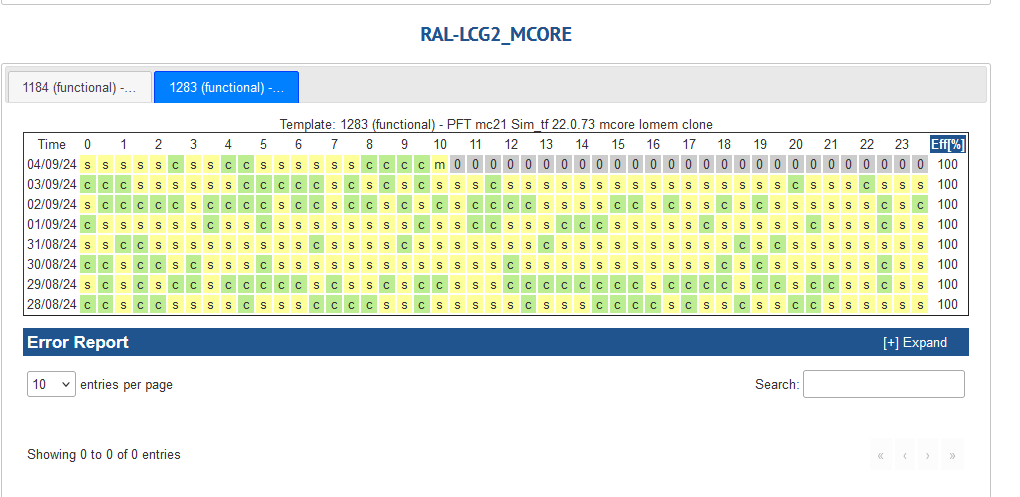
- HC tests are fine.
- Noticed that on the dashboard the state of the job is shown as submitted state and not finished.
- However, when you look closely to the logs, the jobs are actually finished all green.
- its something with HC testing framework and not T1 issue.
- 
## 21-08-2024
### General news
- CRIC migration: An ongoing migration campaign to Python 3 and Alma8 includes core code refactoring, module decoupling, cleanup, etc.
- The overall migration plan is documented [Doc](https://docs.google.com/document/d/1EwgfWiCD69gdIAoXljeRN-3wcCVVeklnuKycbX4rSVg/edit)
- Please contact us if you have any requests related to CRIC.
- SAM / Experiments Test Framework (ETF):
- A hidden dependency on an obsolete protocol (i.e,. gsiftp) affected testing for certain sites (e.g.,
Nikhef, CSC) and their WLCG reliability and availability reports. This issue has been fixed.
- The tests for ARC-CE REST exhibited intermittent errors in pre-production.
- This was identified as an issue with the testing framework, reported to CERN IT, and fixed. These tests will be promoted to production and classified as critical.
- Other issues are under follow-up, such as high memory usage in SAM jobs
- Rucio server issue affecting all clients: Last Friday (17th aug) evening, prompt action by the DDM/Rucio team led to quick mitigation, with medium-term plans ,involving PanDA experts, in place.
- CRIC Update for allowing new granular memory managment by ATLAS.
- Earlier it was only MaxRSS but now its possible to set MeanRSS.
- ATLAS CRIC would needs to be updated for this parameter.
- Manchester updated its Meanrss (3 GB/core) and maxrss (6 GB/core)
### Tier-1 RAL-LCG2
- CPU slot occupancy average (HS23) vs pledge during last week at [111%](https://monit-grafana.cern.ch/goto/PPFlzCjIR?orgId=17)
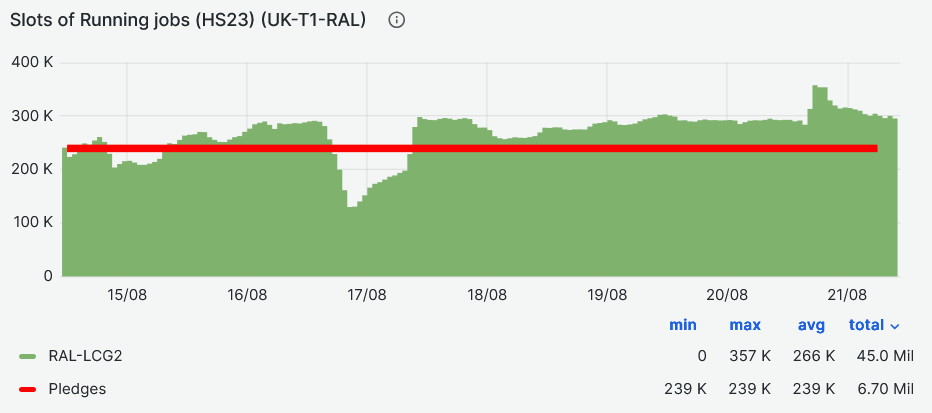
- Walltime efficiency based on success/all accomplished jobs at [95%](https://monit-grafana.cern.ch/goto/DF4nmjjIg?orgId=17)
- Transfer efficieies at - [97%](https://monit-grafana.cern.ch/goto/DF4nmjjIg?orgId=17)
- Much better than last week's 91%
- Hammercloud couple of reds, being investigated [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- No ATLAS VO specific ticket in the system.
## 14-08-2024
***Due to conflict with another meeting, I might get late. ( But i didn't get late and I was able to connect on time :) )***
### General news
- ATLAS SAM tests should no longer require GridFTP protocol (source)
- New tests using REST ARC-CE are available in preproduction, but they are not stable yet.
- FYI: A new version of the CVMFS client (CernVM-FS 2.11.4) is there since last week.
### RAL-LCG2
- The weekly file dumps have been stalled for echo after 26 June. [Jira](https://stfc.atlassian.net/browse/CS-184)
- Is there any further news regarding the file dumps? Since last month, there have not been any new dumps at Echo and Antares (these used to be a weekly affair)!
- CPU slot occupancy average (HS23) vs pledge during last week at [130%](https://monit-grafana.cern.ch/goto/OV_b6OjSR?orgId=17)
- Walltime efficiency based on success/all accomplished jobs at [94.5%](https://monit-grafana.cern.ch/goto/iLp9eOCSg?orgId=17)
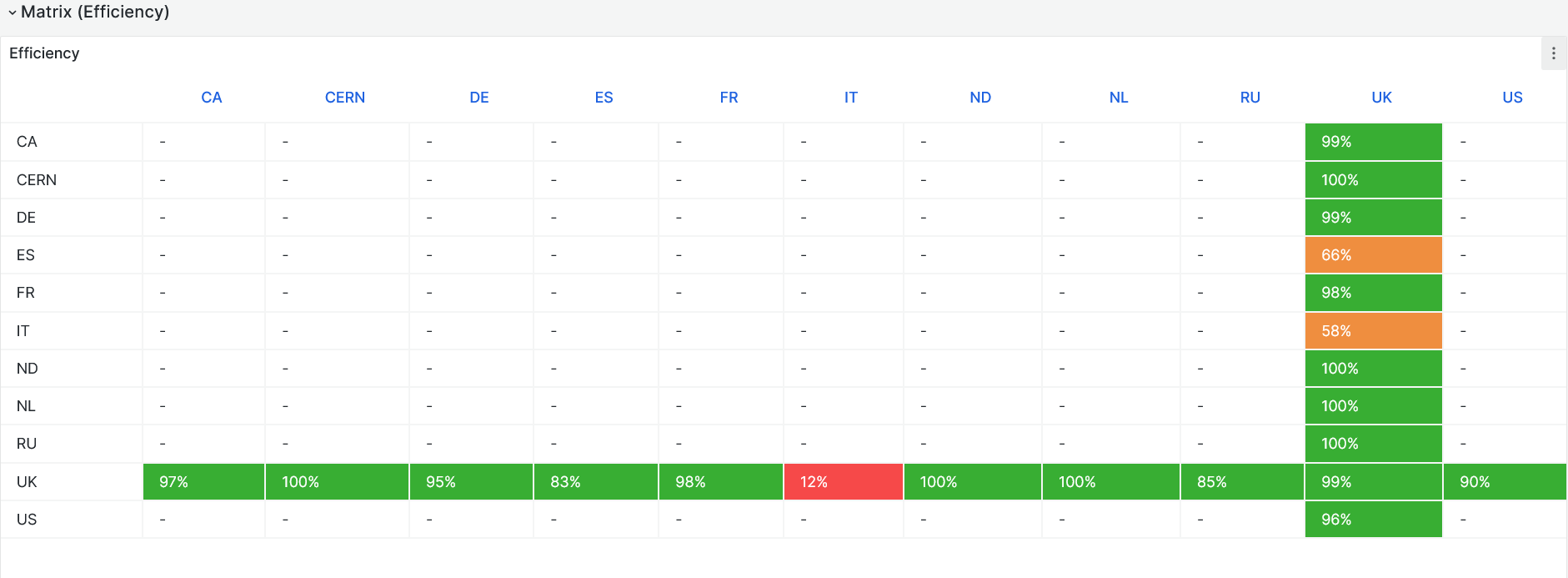
- Transfer efficieies low at 91% (still due to problems at INFN-T1 and Es-T1 end due to dcache bug) - [Link](https://monit-grafana.cern.ch/goto/iLp9eOCSg?orgId=17)
- 
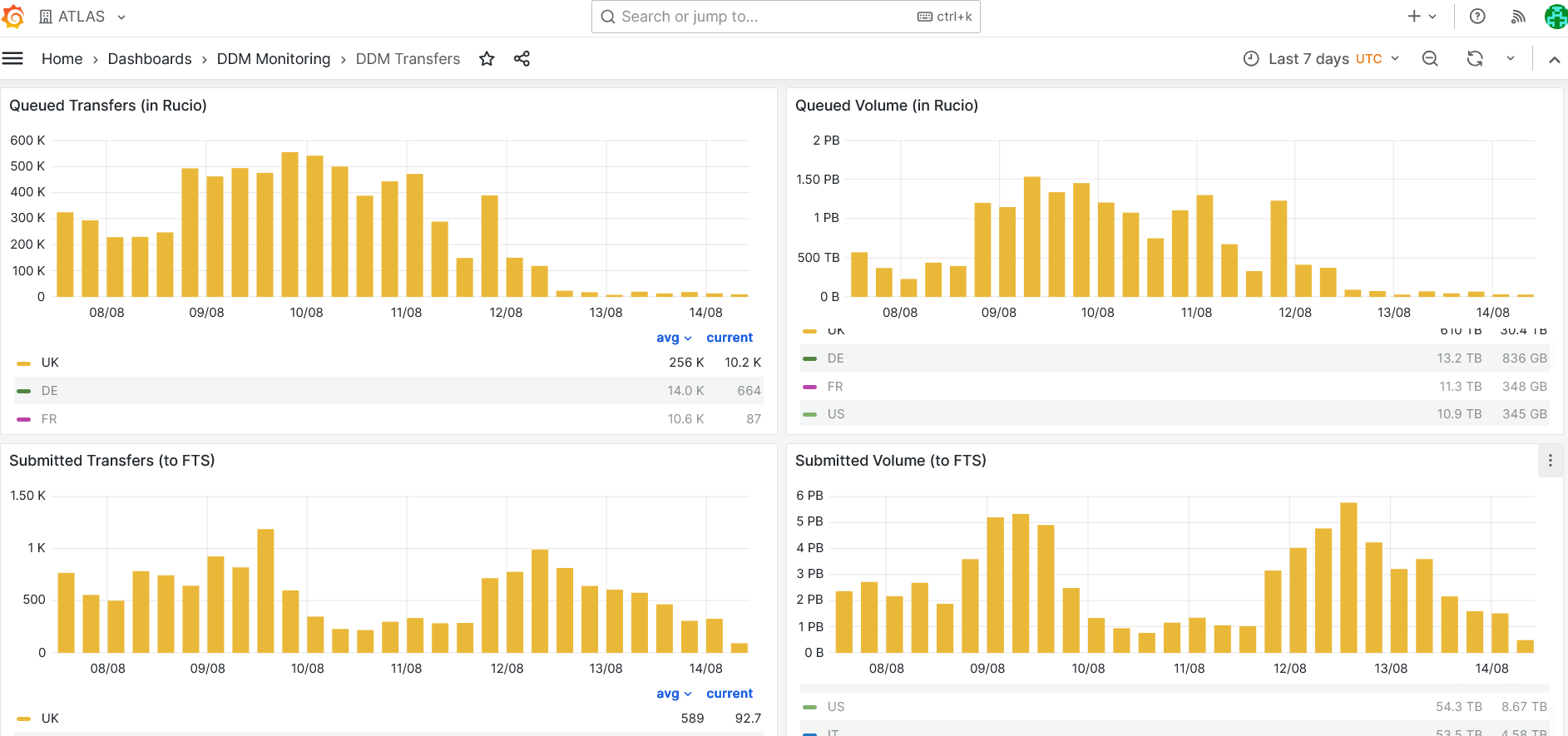
- Data transfers requests during last week
- 
- Hammercloud couple of reds, discussed with data-services, issues known. [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- No ATLAS VO specific ticket in the system.
## 07-08-2024
### RAL-LCG2
- CPU slot occupancy average (HS23) vs pledge during last week at [120%](https://monit-grafana.cern.ch/goto/FTtQo-9Ig?orgId=17)
- This shows that the new scheduling policy is very effective and will allow us to cover the shortfalls in pledge delivery during previous quarter
- Transfer efficieies low at 89% due to problems on INFN-T1 and Es-T1 end - [Link](https://monit-grafana.cern.ch/goto/Vanfo-9Ig?orgId=17)
- Walltime efficiency based on success/all accomplished jobs at [92%](https://monit-grafana.cern.ch/goto/Vanfo-9Ig?orgId=17)
- Due to xrootd gateway failures on friday ?, stable during weekend and thereafter.
- Hammercloud all clear except on friday due to same issue [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- No ATLAS specific ticket
## 24-07-2024
### General News
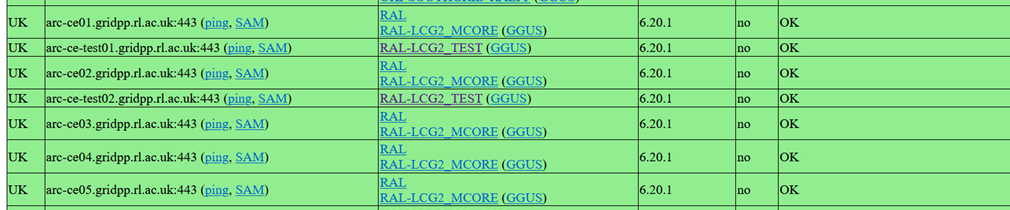
- Updated ARC-CE REST [status summary page](https://testbed.farm.particle.cz/ce/arc-rest/) that now allows to initiate simple [ARC-CE test with tokens](https://testbed.farm.particle.cz/cgi-bin/arc.cgi) (Nordu Arc-CE [bug#4186](https://bugzilla.nordugrid.org/show_bug.cgi?id=4186))
- No, RAL-LCG2 CEs are not passing the token test
- 
### RAL-LCG2
- Slot occupancy at 82% [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17#)
- 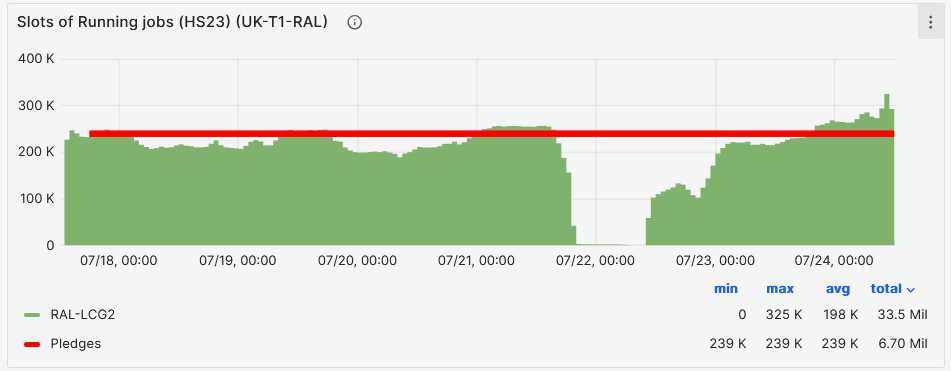
- breaching the pledge, is it because of schedulling changes ?
- Job Walltime efficiency **~85%**[Link](https://monit-grafana.cern.ch/goto/rJzzWLXIg?orgId=17)
- Data Transfer efficiency **~90%** [Link](https://monit-grafana.cern.ch/goto/rJzzWLXIg?orgId=17)
- Drops mainly due to CRL issue
- Open ticket - [CRL 167651](https://ggus.eu/index.php?mode=ticket_info&ticket_id=167651)
- Can be closed
- [HC stable after CRL issue](https://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&startTime=2024-07-19&endTime=2024-07-24&templateType=isGolden)
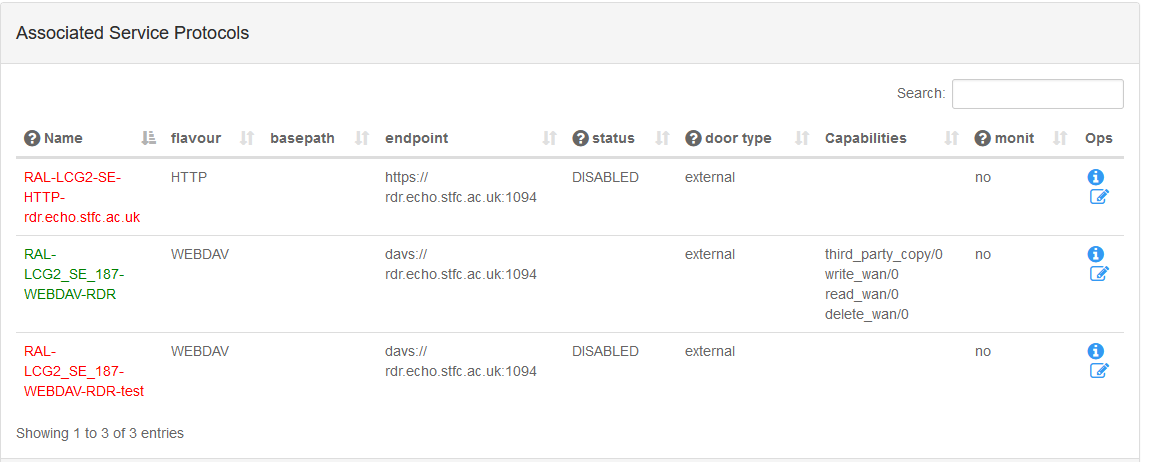
- Updated the Echo Disk test endpoint, Thanks @Brian
- 
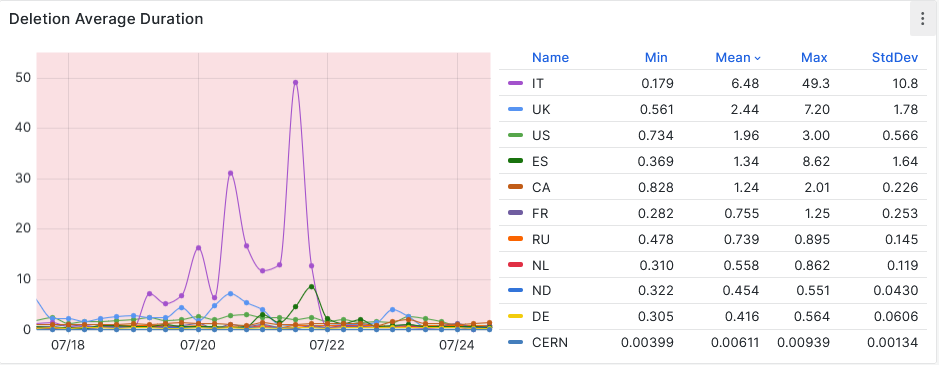
- 
- Requested to Join "New Task-force on multi-core/whole-node scheduling"
- Julia Andreeva confirmed, Thanks @Alastair
## 17-07-2024
I have to chair a seminar session at Picavence today starting at 14:00, so connected from remote.
### General news from ATLAS
- [ATLAS SAM](https://etf-atlas-prod.cern.ch/etf/check_mk/index.py?start_url=%2Fetf%2Fcheck_mk%2Fview.py%3Fview_name%3Dallhosts_mini) will be updated to use ARC-CE REST for tests
- [WLCG coordination meeting notes](https://twiki.cern.ch/twiki/bin/view/LCG/WLCGOpsMinutes240711)
```
- ATLAS Highlight
Good job mix — Primarily consisting of full simulation, group production and MC Reconstruction tasks
Average of 600K slots, peaking at 700k
Daily file transfers ranging from 2M to 3M, with a volume of 3 to 7.5PB
Reached 1 exabyte of data managed in Rucio
- Noted unavailability of ATLAS IAM VOMS service during the week (e.g., OTG:0150883)
```
- [WLCG-GDB](https://indico.cern.ch/event/1356136/#7-mw-availability-el7-eol) updates presented 10th July
- [HePIX Tech Watch reports, CPU trends](https://indico.cern.ch/event/1356136/contributions/6029854/attachments/2894065/5073802/HEPiX-Techwatch-GDB-July-10.pdf)
### RAL-LCG2
- ATLAS job pressure went down on the night of 15th, [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17#)
- This was noticed on morning of 16th, It was beacuse EL7 queues were shutdown by batch-farm team and there were production EL8 queues but there was EL8 queue in Test.
- 5 Production queues, one per CE were put in place and Job pressure is back to normal.
- [Notice@Tier1-batch-farm](https://scdsystems.slack.com/archives/C051MSYBS3E/p1721127110076569)
- As a result of this dip, the CPU slot occupancy average vs pledge during last week at ~80%
- In general, we have to find a way to increase the ATLAS job occupancy.
Average slot occupancy during last 6 month has been at [~84%](https://monit-grafana.cern.ch/goto/uBFlymuSg?orgId=17)
- Looking at the distributions of total ATLAS CPU slot occupancy, about 5% of it might be attributed to at times due lack of jobs in the system
- Is it purely because of single core / multicore limitation ?
- Its clear that Multicore pilots are going to dominate the ATLAS workflows in the future.
- Open for suggestions from batch-farm team.
- Noticed intermittent HC failures yesterday with following error.- [Ongoing discussion @ Data-services](https://scdsystems.slack.com/archives/CUY6TBWKV/p1721140118176019)
```
pilot, 1324: Service not available at the moment:
mc21_13p6TeV:EVNT.29070483._000239.pool.root.1
from RAL-LCG2-ECHO_DATADISK, Error on XrdCl:CopyProcess:Run():
[ERROR] Server responded with an error: [3008] cannot allocate memory
(source)')]:failed to transfer files using copytools=['rucio']
```
- no failures noticed since yesterday evening [HC dashboard](https://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&startTime=2024-07-10&endTime=2024-07-18&templateType=isGolden)
- Job Walltime efficiency **~95.5%**[Link](https://monit-grafana.cern.ch/goto/m9SJgeQSR?orgId=17)
- Data Transfer efficiency **~99.5%** [Link](https://monit-grafana.cern.ch/goto/m9SJgeQSR?orgId=17)
## 10-07-2024
### General news from ATLAS
From CRC:
* ATLAS IAM VOMS not available since yesterday morning [OTG0150883](https://cern.service-now.com/service-portal?id=outage&n=OTG0150883)
* OpenShift control plain down [OTG0150648](https://cern.service-now.com/service-portal?id=outage&n=OTG0150648) - impossible to restart pods
### RAL-LCG2
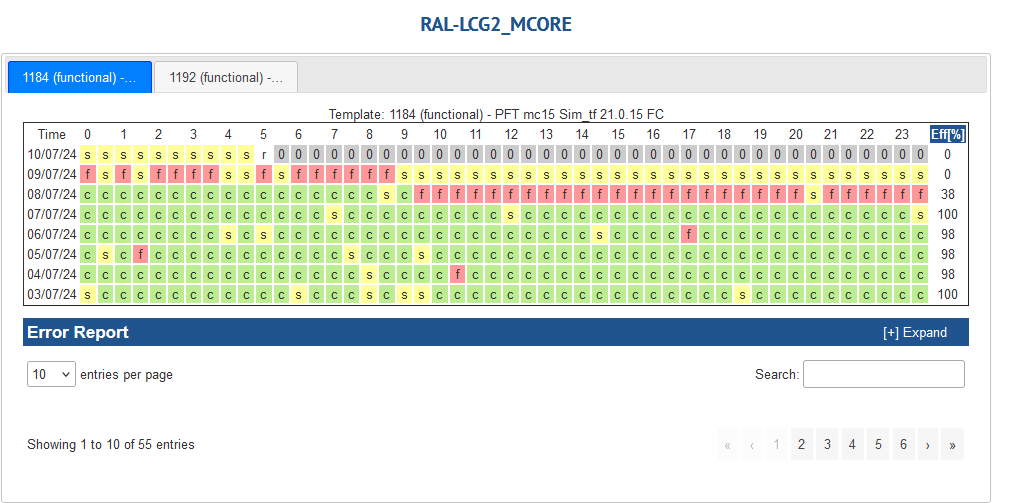
- CPU slot occupancy average vs pledge during last week at **~88** [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17)
- Hammercloud, All green for normal RAL queue but [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- Quite a lot of red for RAL-LCG2_MCORE
- Job error ` taskbuffer, 300: The worker was finished while the job was starting : None`
- 
- Job Walltime job efficiency **~98%**[Link](https://monit-grafana.cern.ch/goto/m9SJgeQSR?orgId=17)
- Data Transfer efficiency **~99%** [Link](https://monit-grafana.cern.ch/goto/m9SJgeQSR?orgId=17)
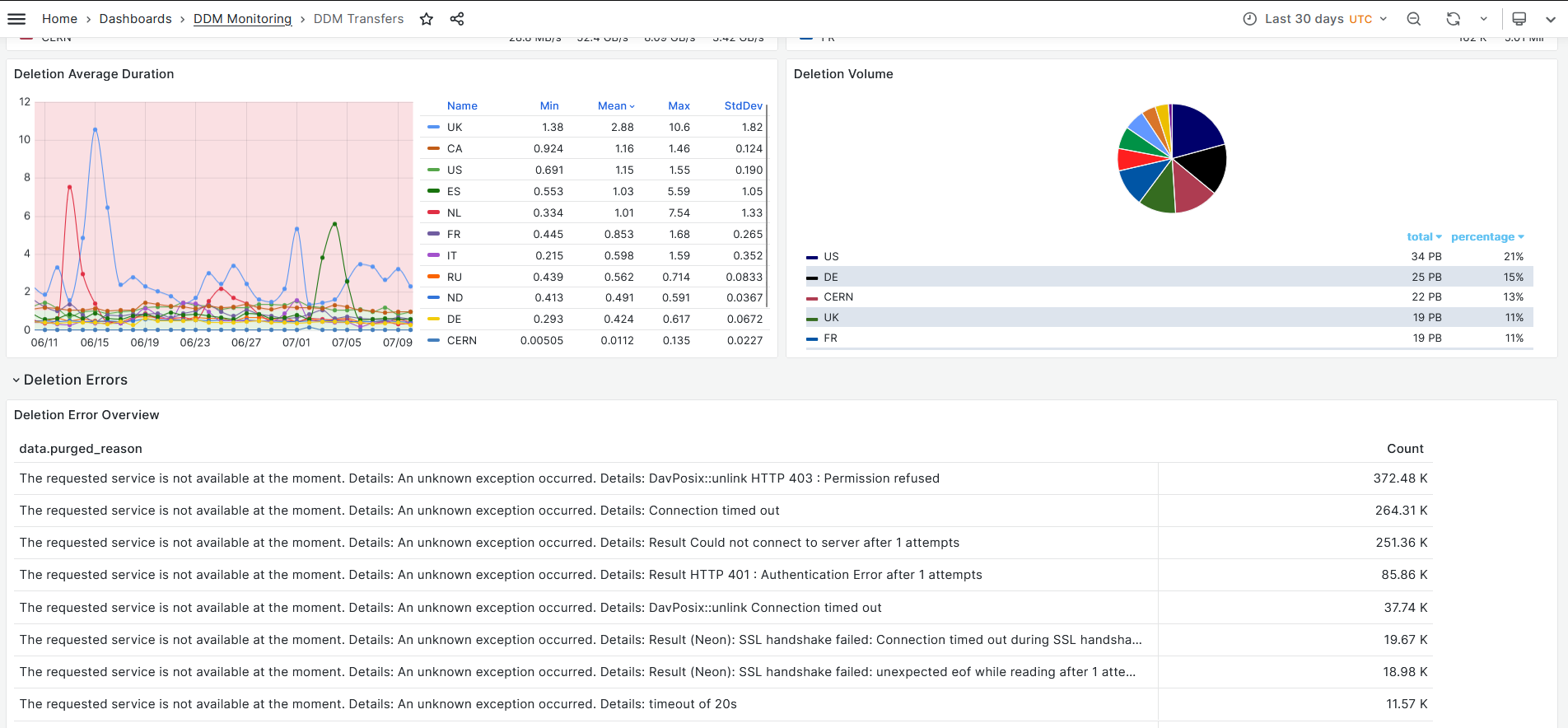
- DDM dashboard [link](https://monit-grafana.cern.ch/goto/AMi6OA_SR?orgId=17)
- Deletions last 30 days
- 
## 03-07-2024
### General news from ATLAS
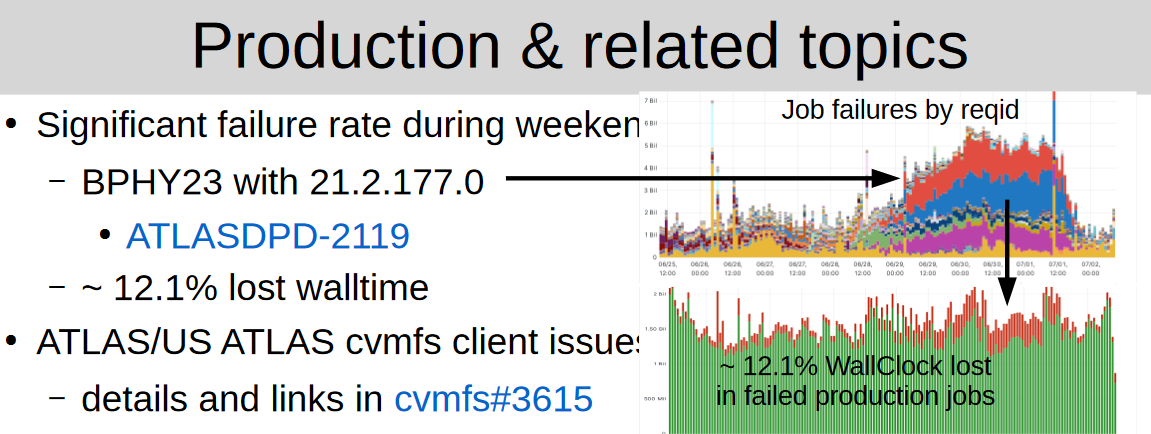
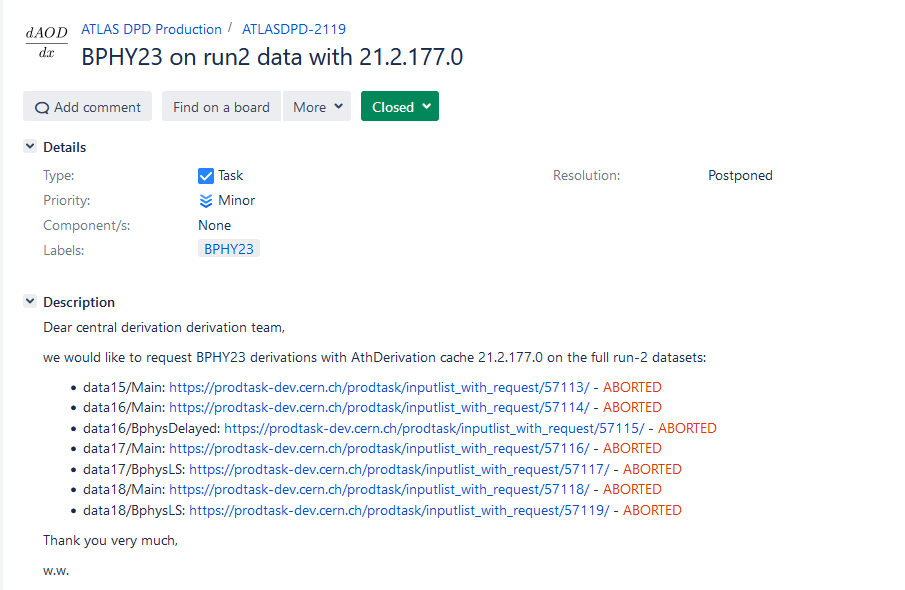
- Bad workflows, spiked prod failures during the weekend have been aborted.
* 
* 
- Ongoing discussions to roll out more granular memory flavors for jobs
- Currently we only divide in normal and high memory (2GB/core and >2GB/core)
- We want to gradually add 1GB/core steps in the least intrusive way
### RAL-LCG2
- CPU slot occupancy average vs pledge during last week at **~94** [Link](https://monit-grafana.cern.ch/goto/dFjTR6QSR?orgId=17)
- Hammercloud, All green [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- Job Walltime job efficiency **~84%**[Link](https://monit-grafana.cern.ch/goto/m9SJgeQSR?orgId=17)
- Data Transfer efficiency **~98%** [Link](https://monit-grafana.cern.ch/goto/m9SJgeQSR?orgId=17)
## 26-06-2024
### General news from ATLAS
- Data deletion campaign: The Lifetime Model will be applied soon to delete old and unused data. The files to be deleted are [available here](https://atlas-adcmon.cern.ch/lifetime-model/results/latest/beyond-lifetime-centrally-managed/) or at /eos/user/d/ddmusr01/shared/lifetime-model/latest/everything.txt.gz. Instructions on how to submit an exception request are [provided here](https://twiki.cern.ch/twiki/bin/view/AtlasComputing/DDMLifetimeModel#Exception_Requests). The deadline for exceptions is July 4.
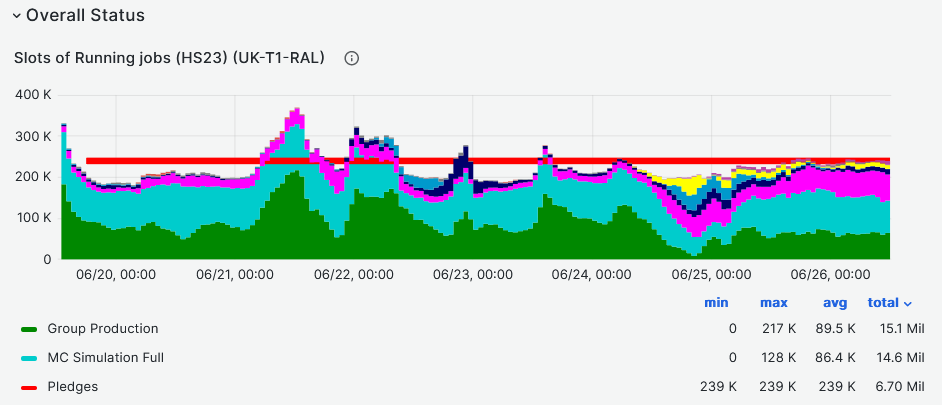
### RAL-LCG2
- CPU slot occupancy average vs pledge during last week at **~95** [Link](https://monit-grafana.cern.ch/goto/cUsdqcwIg?orgId=17)
- Hammercloud, Green [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
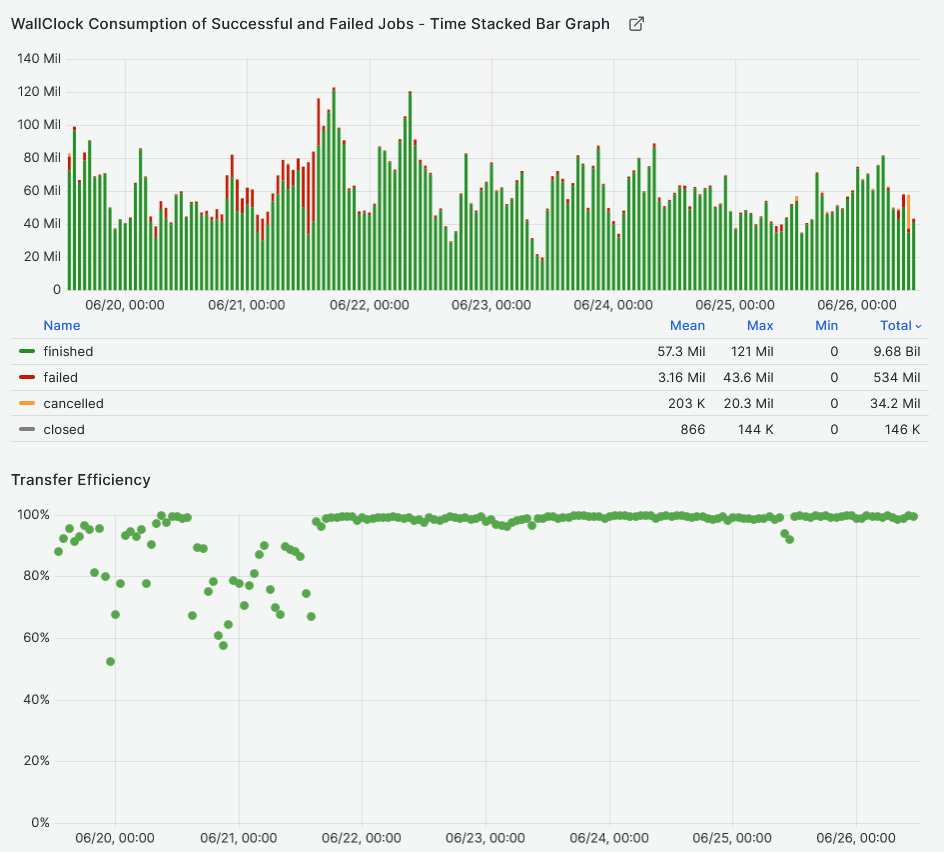
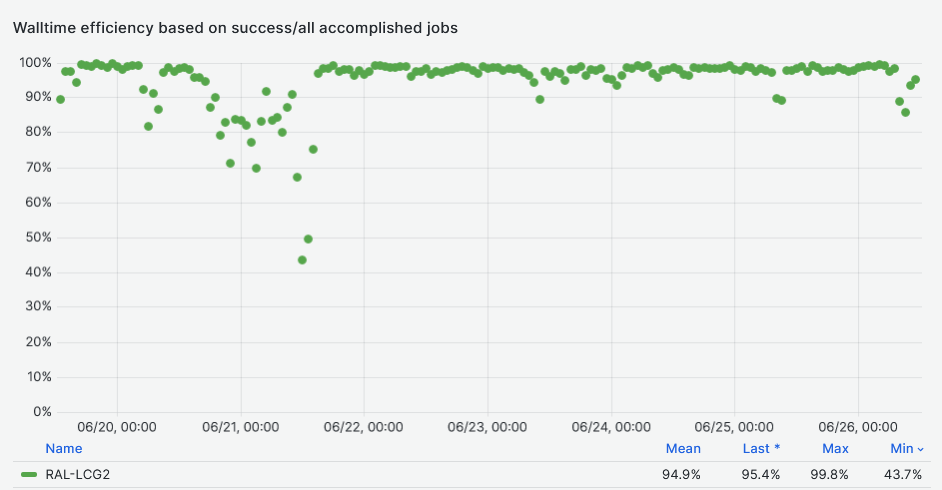
- Job Walltime job efficiency **~95%**[Link](https://monit-grafana.cern.ch/goto/GavzgtQSg?orgId=17)
- Data Transfer efficiency **~95%** [Link](https://monit-grafana.cern.ch/goto/GavzgtQSg?orgId=17)
- 
- 
- 
## 19-06-2024
### General news
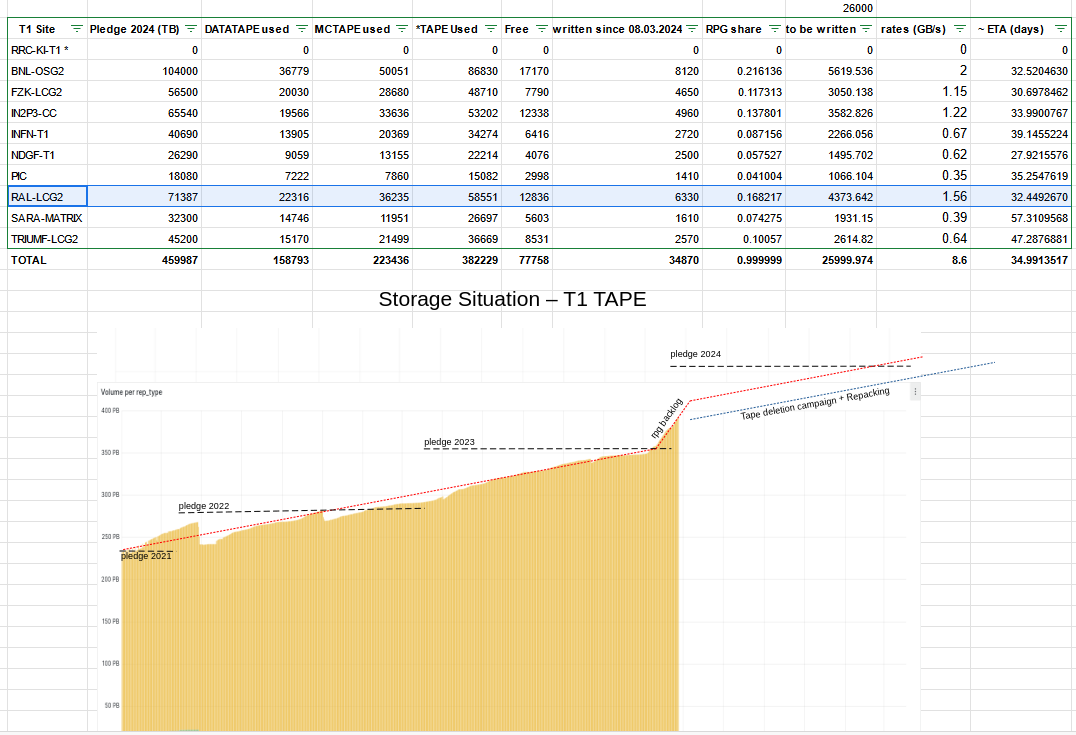
- [Data Consolidation Campaign](https://docs.google.com/spreadsheets/d/1YqJSY-ssBboQp_ATHCa05A70ouugL76vrs55Rn-G4o8/edit?gid=0#gid=0) on MCTAPE is over
- 
- Follow-up on last ATLAS software week and computing support for Storageless sites,.i.e., VP queues and xcache support — Cf. Ilija's talk
- Ongoing discussion on organizing first-level support (service monitoring, etc.) within ADC
- New contributor for Rucio dev from UK to help with geolocation fixes etc
### RAL-LCG2
Xrootd problems:
- Authentication gets forgetten
- Memory overflow bug in xrootd over EL8.
Echo has been upgraded to Roccky8:
- Open ticket
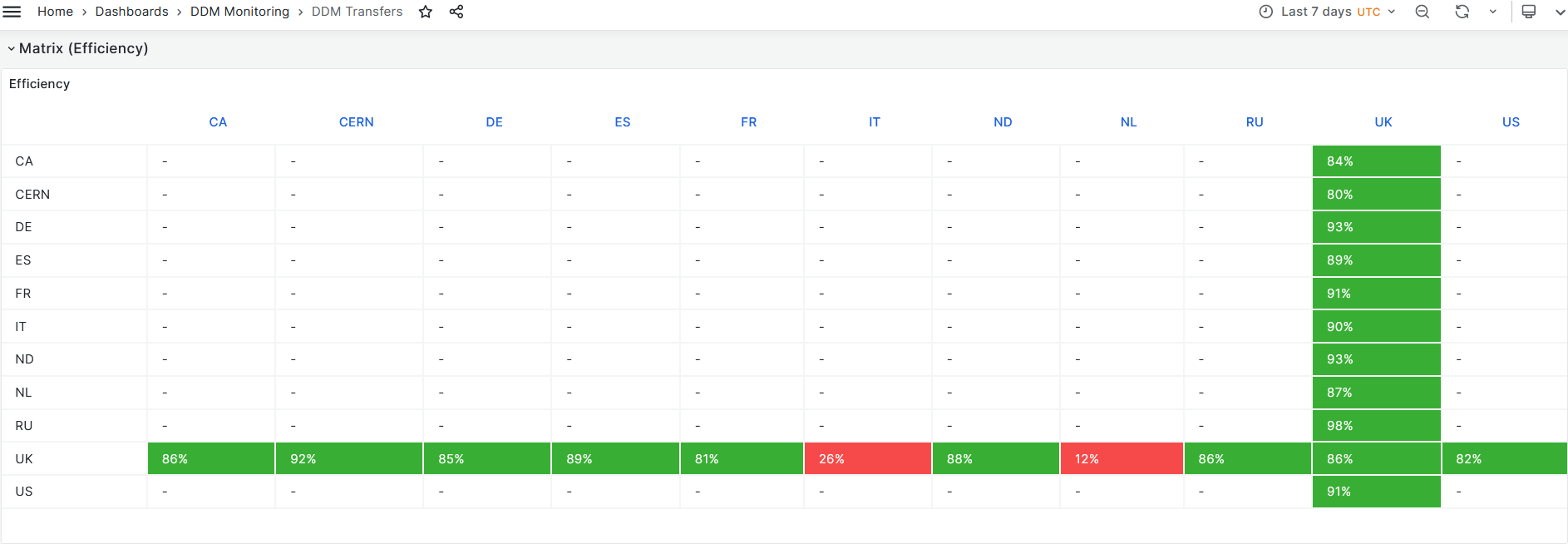
RAL-LCG2: transfer failures as a dest and deletion failures Open ggus ticket: [167117](https://ggus.eu/index.php?mode=ticket_info&ticket_id=167117)
- CPU slot occupancy average vs pledge during last week - **~65%** [Link](https://monit-grafana.cern.ch/goto/DifhCl8Sg?orgId=17)
- Job Walltime job efficiency **~88%**[Link](https://monit-grafana.cern.ch/goto/UwJbj_USg?orgId=17)
- Data Transfer efficiency **~87%** [Link](https://monit-grafana.cern.ch/goto/UwJbj_USg?orgId=17)
- Hammercloud, colourfull [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- DDM dashboard [Link](https://monit-grafana.cern.ch/goto/l0ozrH8SR?orgId=17)
- IT and NL failing with everyone else as well.
- 
- 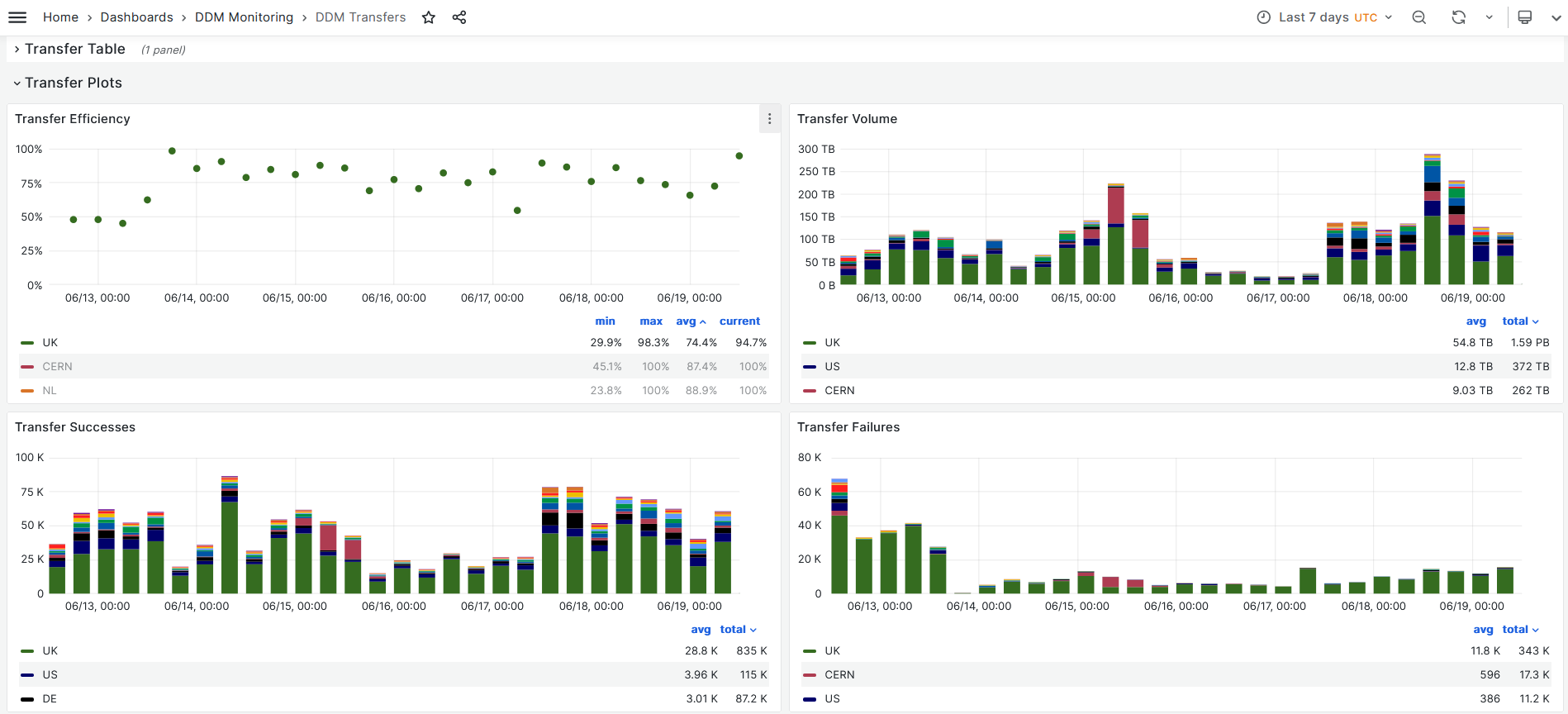
- Error in last few hours
- TRANSFER ERROR: Copy failed (3rd pull). Last attempt: Connection terminated abruptly; Status of TPC request unknown
- 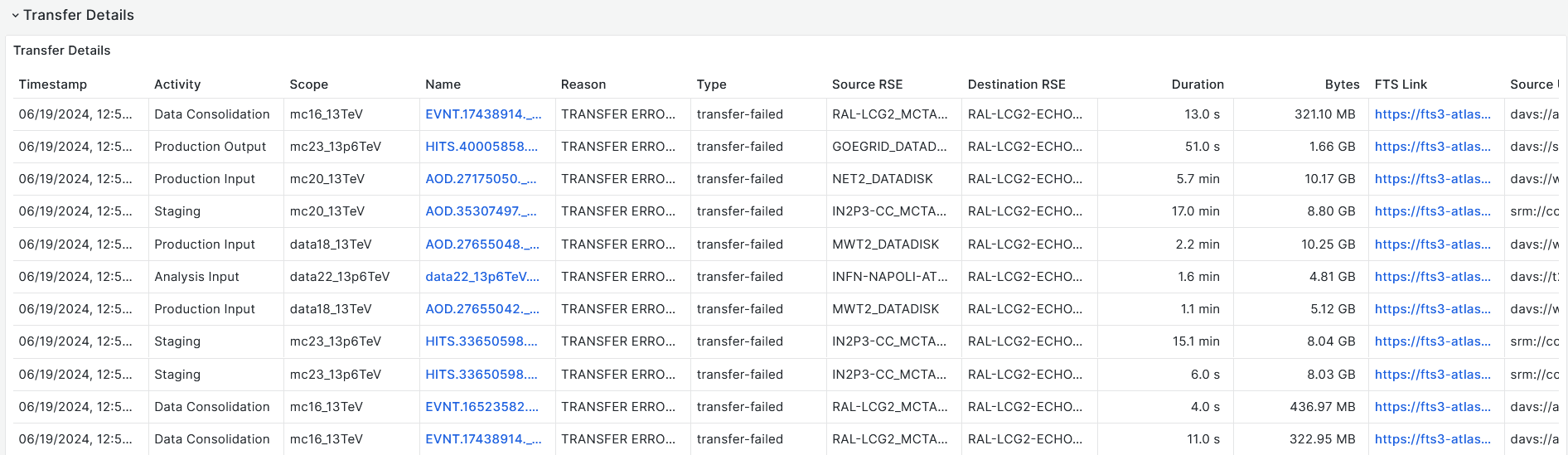
- DESTINATION MAKE_PARENT HTTP 403 : Permission refused
- 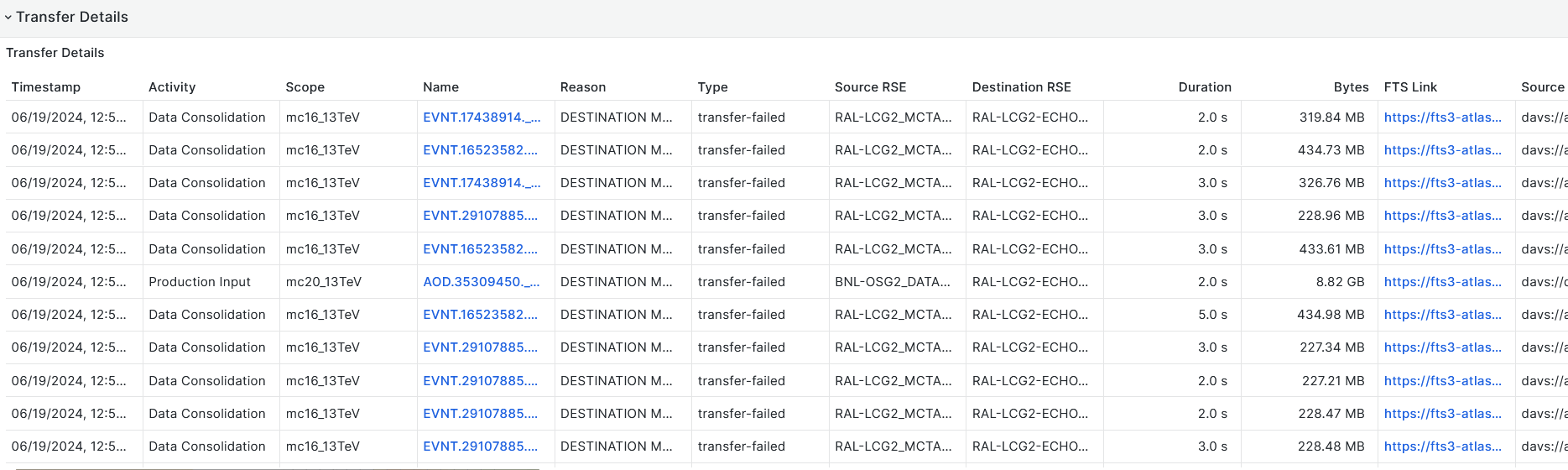
- DESTINATION OVERWRITE Result curl error (35): SSL connect error after 1 attempts
## 12-06-2024
### General news
* [ATLAS Software & Computing Week #78](https://indico.cern.ch/event/1334594/timetable/) Summary of the week presentation at tomorrows ATLAS UK Cloud support meeting
* Good discussion on ATLAS VP queues, communicated UK's point of view.
* Nothing else which stands out just specific to RAL Tier-1
- Open tickets: None
- Multiple UK ATLAS sites commissioning and testing new EL9 CEs and endpoints.
### RAL-LCG2
- RAL ATLAS Tier1(RAL-LCG2) Availability/Reliabiity for the past week - **100%** [Link](https://monit-grafana.cern.ch/goto/3TUVXN8Ig?orgId=17)
- CPU slot occupancy average vs pledge during last week - **~100.5% Hurrey** [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17#)
- Job Walltime job efficiency **~98%**[Link](https://monit-grafana.cern.ch/goto/gFnwuNUSR?orgId=17)
- Data Transfer efficiency **~99%** [Link](https://monit-grafana.cern.ch/goto/gFnwuNUSR?orgId=17)
- Hammercloud all green [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
- DDM dashboard [Link](https://monit-grafana.cern.ch/goto/l0ozrH8SR?orgId=17)
- 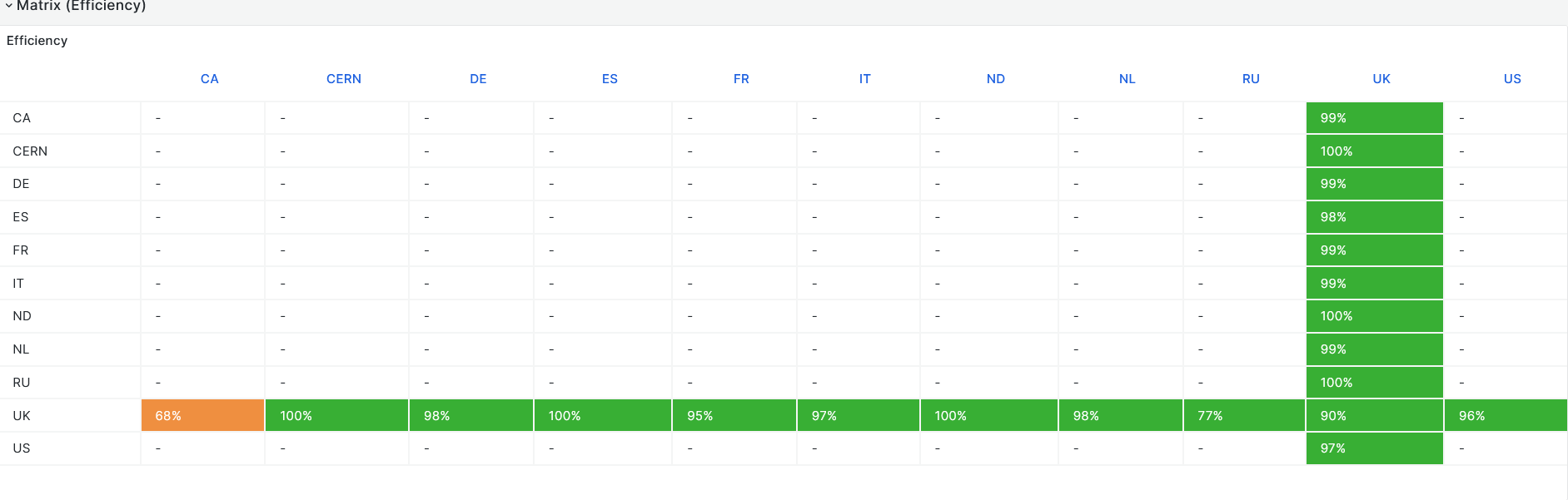
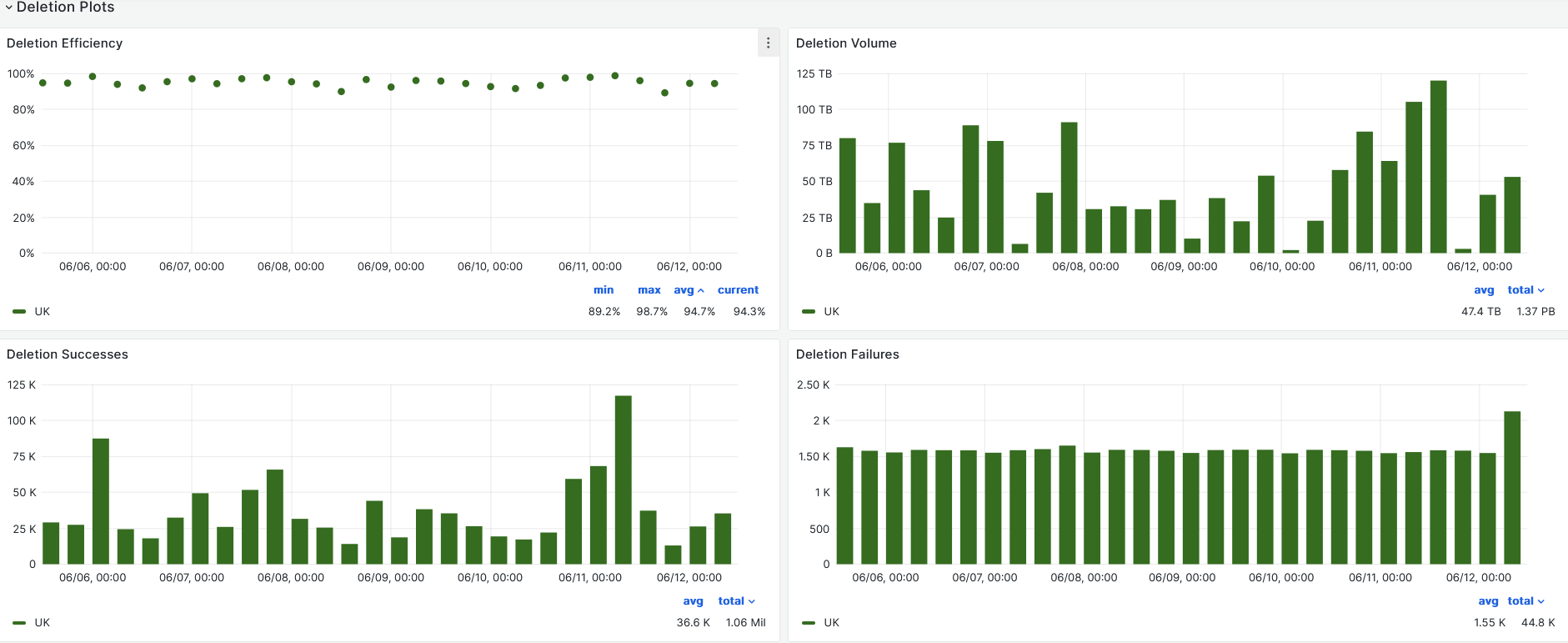
- DDM Deletions [Link](https://monit-grafana.cern.ch/goto/NB2GjHUSg?orgId=17)
- 
- DDM deletions [Link 2](https://monit-grafana.cern.ch/goto/h0u-qH8Sg?orgId=17)
- 
## 05-06-2024
Apologies for not being able to connect (Brij)
- Ongoing: Currently at ATLAS S&C week at Oslo (3 - 7 June)
- Open tickets: None
- RAL ATLAS Tier1(RAL-LCG2) Availability/Reliabiity for the past week - **100%** [Link](https://monit-grafana.cern.ch/dashboard/snapshot/teug2QTCcEO4bgKEdGc0nObz2nckxlBL)
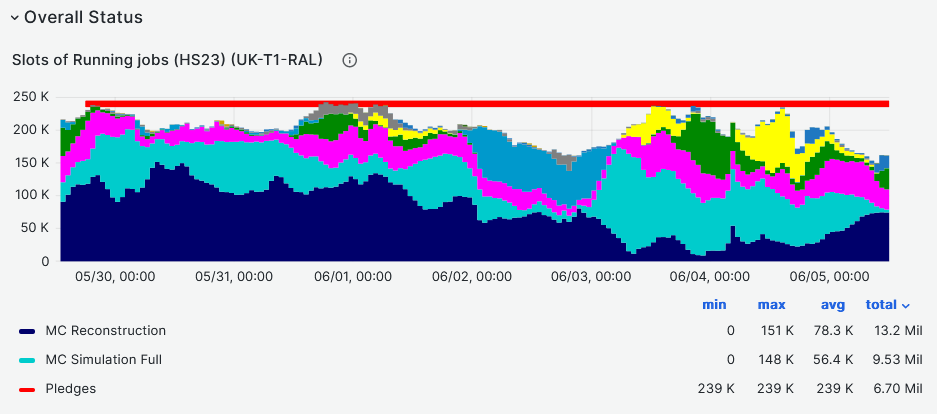
- CPU slot occupancy average vs pledge during last week - **~85%** [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17#)
- Is it just low job pressure from ATLAS side ? Not sure, but there are low MC and reconstruction workflows
- 
- Job Walltime job efficiency **~98%**[Link](https://monit-grafana.cern.ch/dashboard/snapshot/qy8IAnm6nzcgOKmYgoJNPQxzbfYgsPN4)
- Data Transfer efficiency **~99%** [Link](https://monit-grafana.cern.ch/goto/J53c8MsSg?orgId=17)
- Hammercloud all clear [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
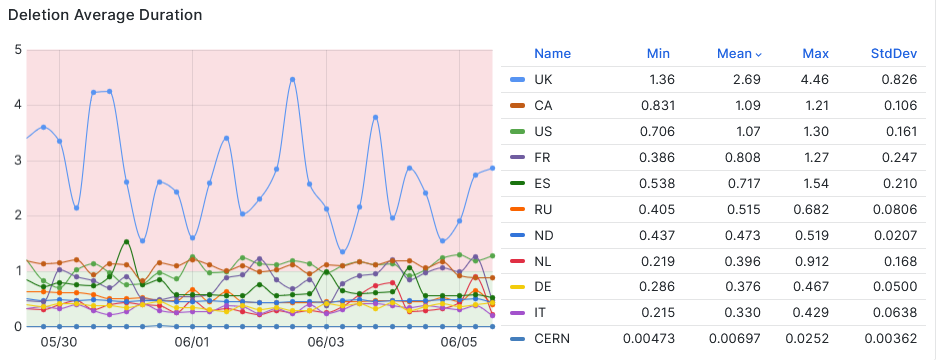
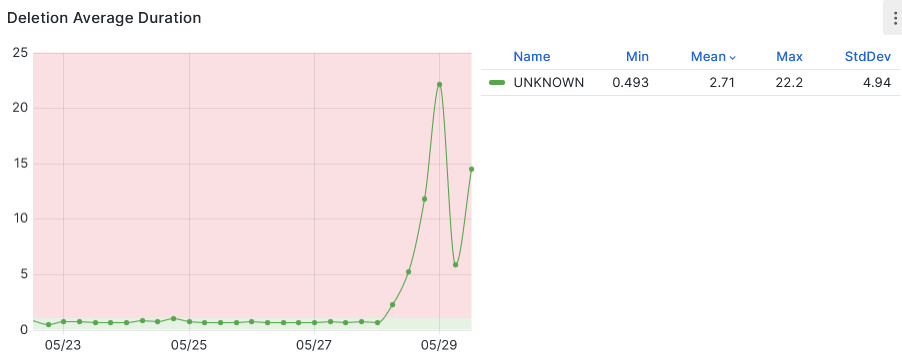
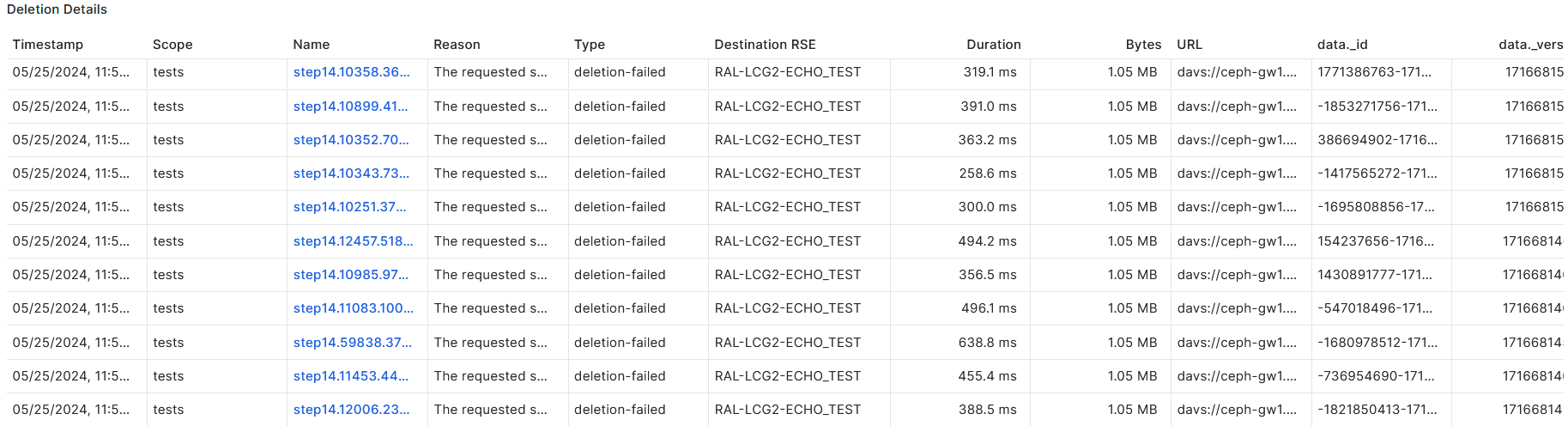
- Tracking DDM deletion status[Link](https://monit-grafana.cern.ch/goto/61fcCEySR?orgId=17)
- Need to investigate why DDM deletion average duration is high for UK as compared to everyone else.
- 
## 29-05-2024
- Next week (3-7 June) at ATLAS S&C week, Oslo
- Open tickets:
- transfer failures from AGLT2 site.[166818](https://ggus.eu/index.php?mode=ticket_info&ticket_id=166818)
- Issue at AGTL network side, being investigated.
- RAL ATLAS Tier1(RAL-LCG2) Availability/Reliabiity for the past week - **100%** [Link](https://monit-grafana.cern.ch/goto/-olg3MsIg?orgId=17)
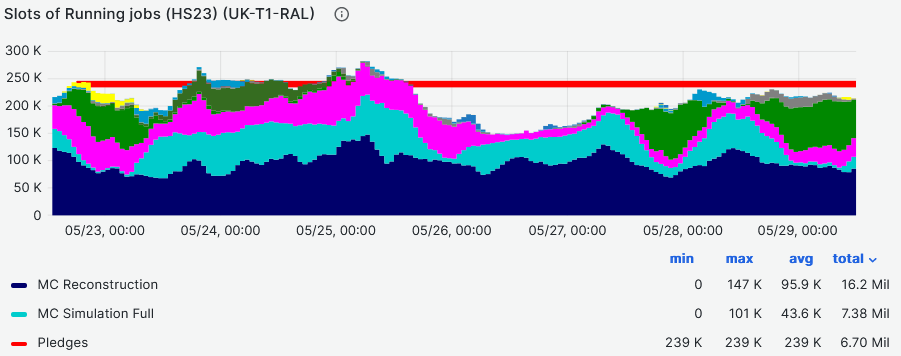
- CPU slot occupancy average vs pledge during last week - **~89%** [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17#)
- Dip due to lack of group productions at times in overall ATLAS queues
- 
- Job Walltime job efficiency **~98%**[Link](https://monit-grafana.cern.ch/goto/J53c8MsSg?orgId=17)
- Hammercloud, a glitch on last thursday in just one set, but rest all clear [Link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&days=7&templateType=isGolden)
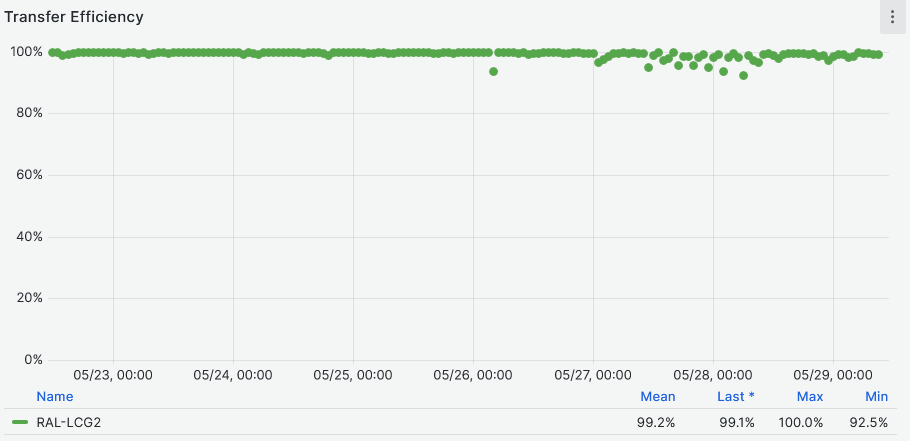
- Data Transfer efficiency **~99%** [Link](https://monit-grafana.cern.ch/goto/J53c8MsSg?orgId=17)
- 
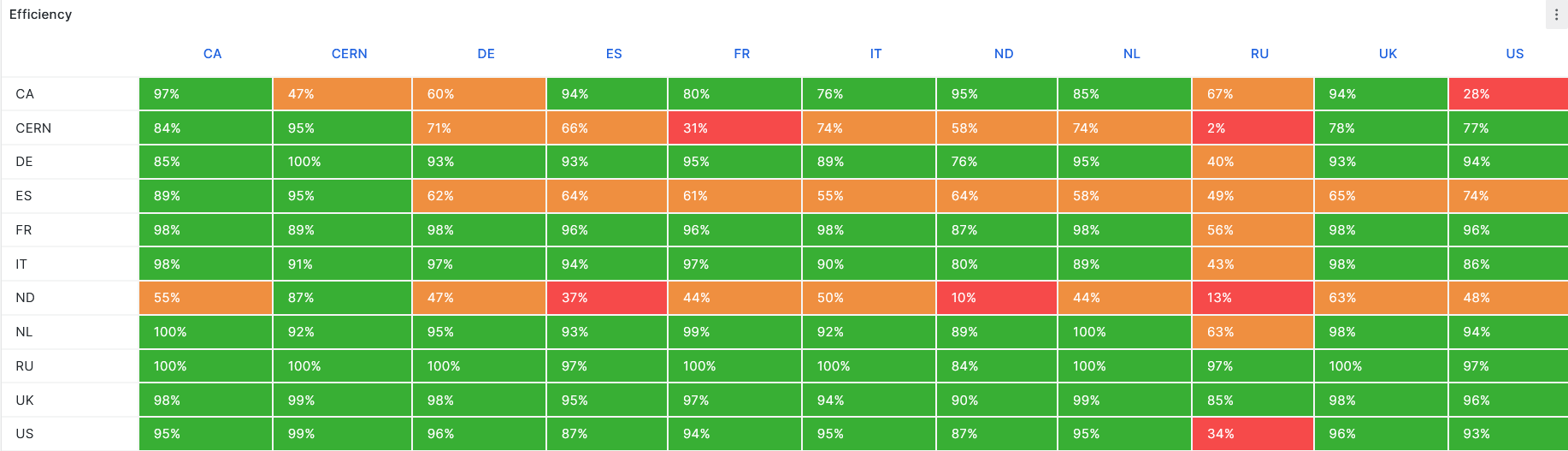
- DDM monitoring overall [Link](https://monit-grafana.cern.ch/goto/0HycqMySg?orgId=17)
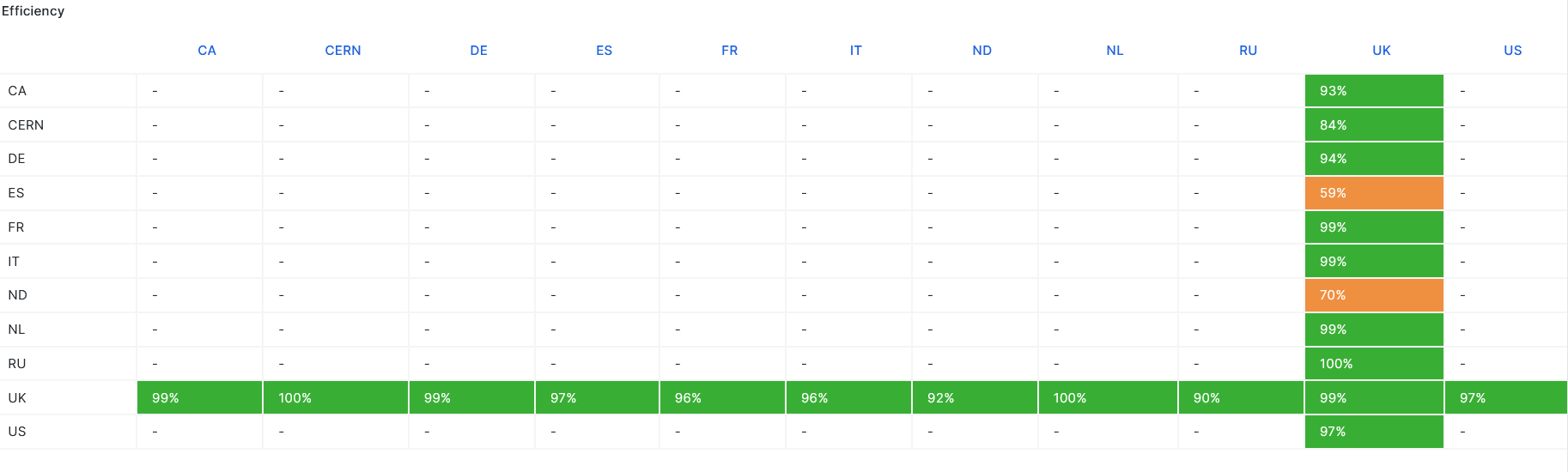
- 
- 
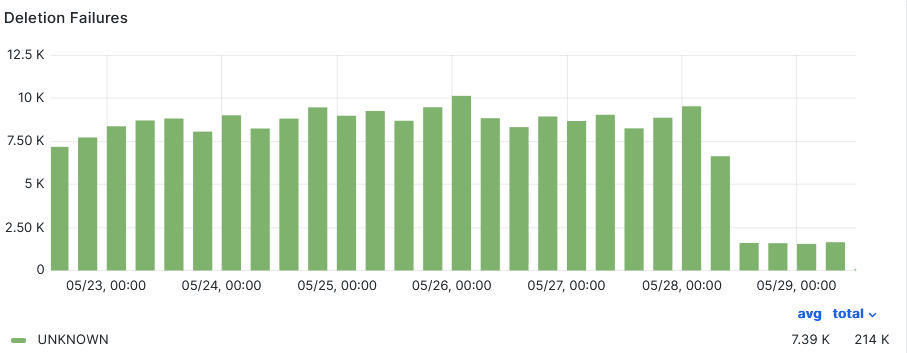
- 
- 
- 
- 
- 
- RAL-LCG2_DATATAPE(TB) Occupancy at **~82%** [Link](http://adc-ddm-mon.cern.ch/ddmusr01/plots/plots.php?endpoint=RAL-LCG2_DATATAPE)
- RAL-LCG2_MCTAPE(TB) Occupancy at **~82%** [Link](http://adc-ddm-mon.cern.ch/ddmusr01/plots/plots.php?endpoint=RAL-LCG2_MCTAPE)
- RAL-LCG2-ECHO_DATADISK(TB) Occupancy at **~98%** [Link](http://adc-ddm-mon.cern.ch/ddmusr01/plots/plots.php?endpoint=RAL-LCG2-ECHO_DATADISK)
## 22-05-2024
- open tickets:
- transfer failures from AGLT2 site.[166818](https://ggus.eu/index.php?mode=ticket_info&ticket_id=166818)
Thanks to the debugging by Jyothish and data-services team, the issues is confirmed to be on the AGLT2 network side
- RAL ATLAS Tier1(RAL-LCG2) Availability/Reliabiity for the past week - **100%** [Link](https://monit-grafana.cern.ch/d/MMv9h33Zk/site-status-board-site-details?orgId=17&var-tier=All&var-country=All&var-federation=All&var-site=RAL-LCG2)
- CPU slot occupancy average vs pledge during last week - **~99%** [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17#)
- Job Walltime job efficiency **~99%**[Link](https://monit-grafana.cern.ch/goto/geD2hbEIR?orgId=17)
- Data Transfer efficiency **~99%** [Link](https://monit-grafana.cern.ch/goto/geD2hbEIR?orgId=17)
- RAL-LCG2_DATATAPE(TB) Occupancy at **~82%** [Link](http://adc-ddm-mon.cern.ch/ddmusr01/plots/plots.php?endpoint=RAL-LCG2_DATATAPE)
- RAL-LCG2_MCTAPE(TB) Occupancy at **~82%** [Link](http://adc-ddm-mon.cern.ch/ddmusr01/plots/plots.php?endpoint=RAL-LCG2_MCTAPE)
- RAL-LCG2-ECHO_DATADISK(TB) Occupancy at **~98%** [Link](http://adc-ddm-mon.cern.ch/ddmusr01/plots/plots.php?endpoint=RAL-LCG2-ECHO_DATADISK)
## 15-05-2024
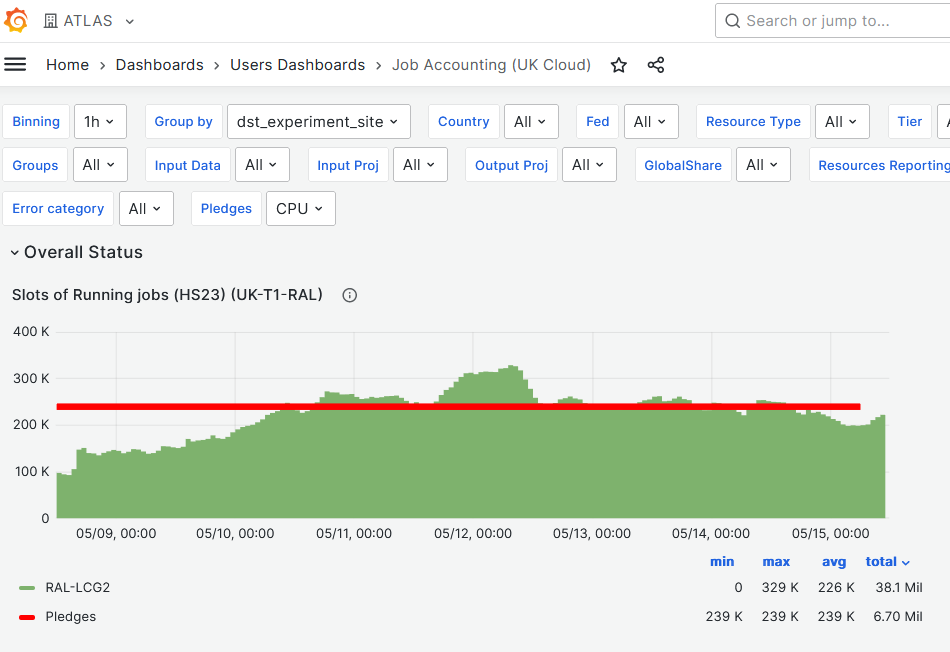
- CPU slot occupancy average vs pledge during last week at **~95%** [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17)
- significantly higher as compared to last week's 52%
- In total about 600K running at ATLAS overall.
- 
- RAL ATLAS Tier1(RAL-LCG2) Availability/Reliabiity for the past week - **100%** [Link](https://monit-grafana.cern.ch/goto/8WmaqYBIg?orgId=17)
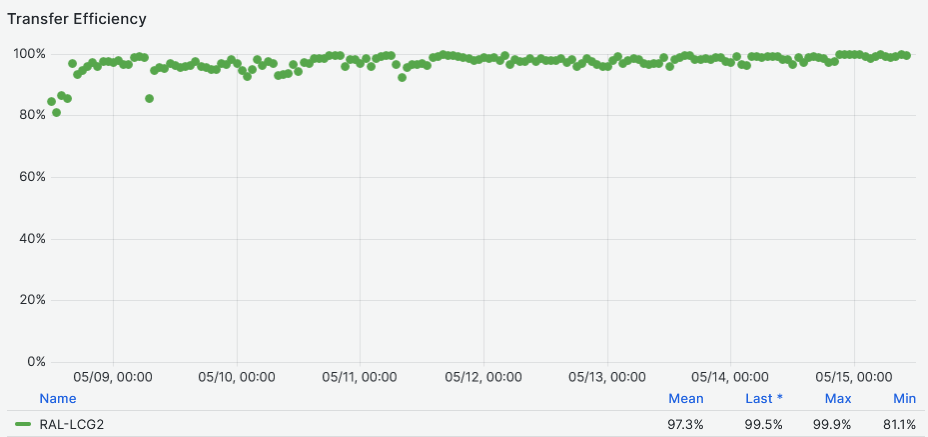
- Data Transfer efficiency **~97%** [Link](https://monit-grafana.cern.ch/goto/3frJu2YIR?orgId=17)
- Significantly better then last week's 88%
- 
- Walltime job efficiency **~98%**[Link](https://monit-grafana.cern.ch/goto/3frJu2YIR?orgId=17)
- Hammer Cloud status all clear [link](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&startTime=2024-05-08&endTime=2024-05-15&templateType=isGolden)
##
## 08-05-2024
- Some important links - [Sites status board](https://cern.ch/ukcloud-site-status-board), [weekly status](https://cern.ch/ukcloud-weekly-site-status), [JobAccountDashboardUKCloud](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17#), [Open ggus tickets](https://cern.ch/open-ggus-tickets-ngi-uk-atlas)
- No open tickets
- CPU slot occupancy average vs pledge during last week - **~52%** [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17)
- 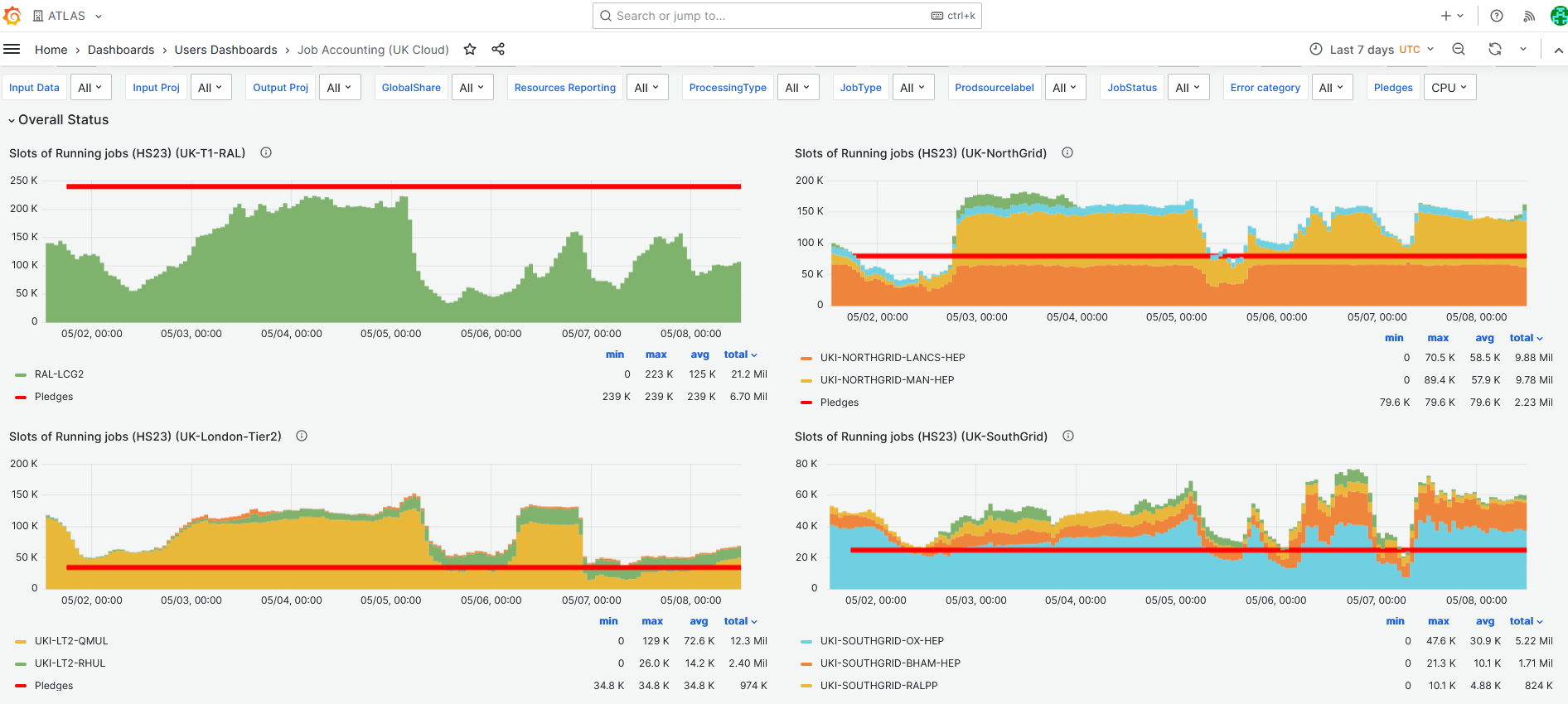
- RAL ATLAS Tier1(RAL-LCG2) Availability/Reliabiity for the past week (Scheduled downtime for one of the CEs) - **100%** [Link](https://monit-grafana.cern.ch/goto/8WmaqYBIg?orgId=17)
- Data Transfer efficiency **~88** [Link](https://monit-grafana.cern.ch/goto/3Y6XwRPIg?orgId=17)
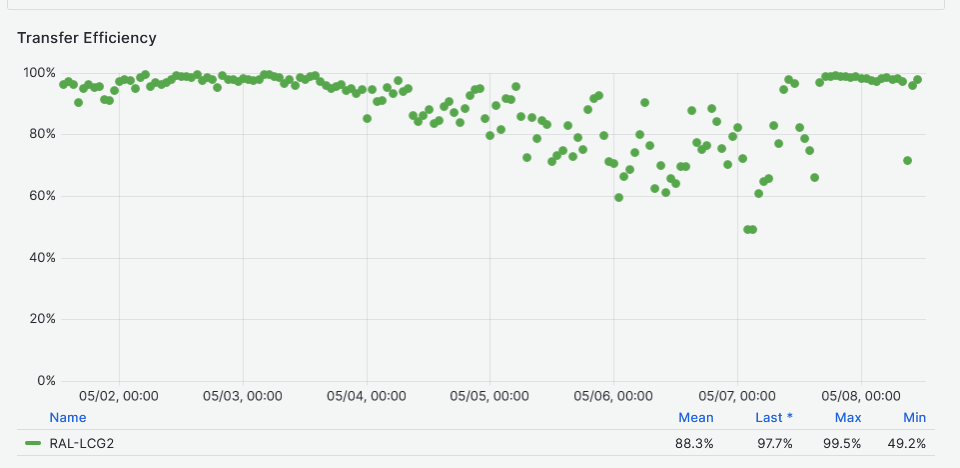
- [Details transfer](https://monit-grafana.cern.ch/goto/TE2NjhLSR?orgId=17)
- Walltime job efficiency **~98%**[Link](https://monit-grafana.cern.ch/goto/7EnYyrBIg?orgId=17)
- Not sure why data is missing from Mon-Tue (TBC)
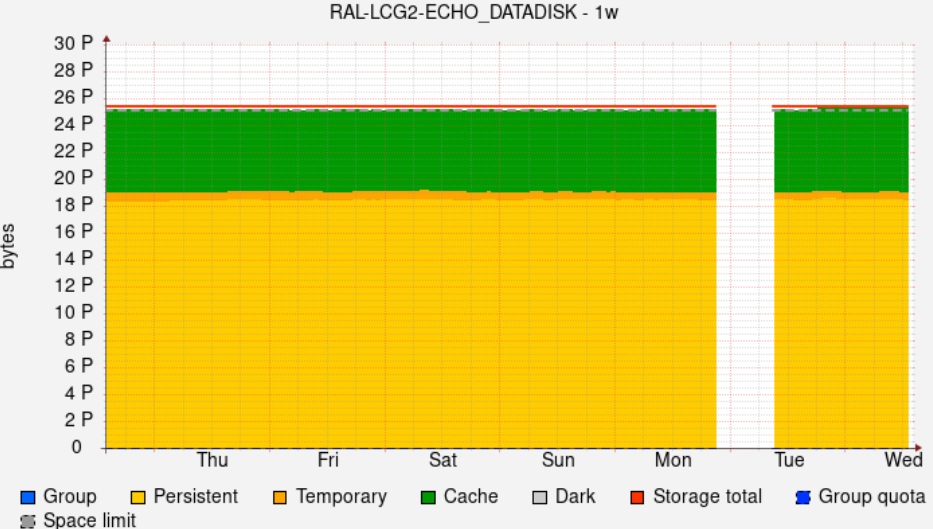
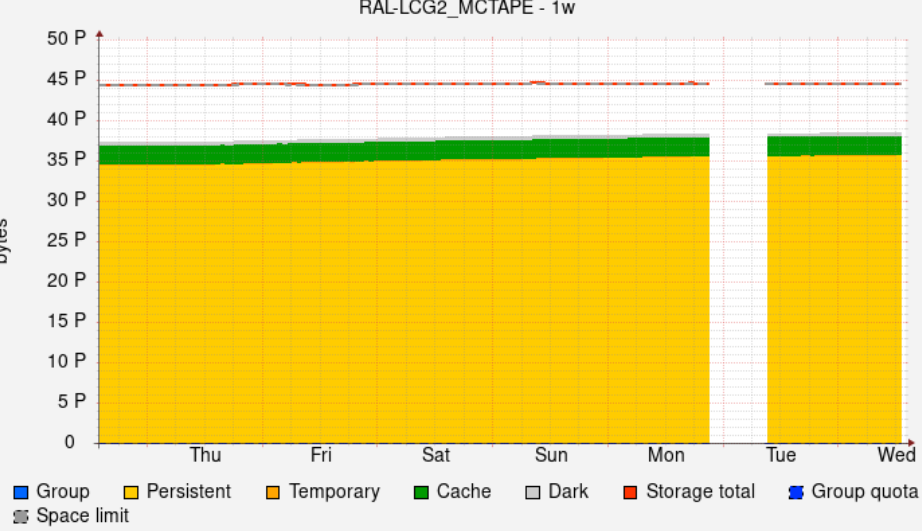
- [HC status](http://hammercloud.cern.ch/hc/app/atlas/siteoverview/?site=RAL-LCG2&startTime=2024-05-01&endTime=2024-05-09&templateType=isGolden)
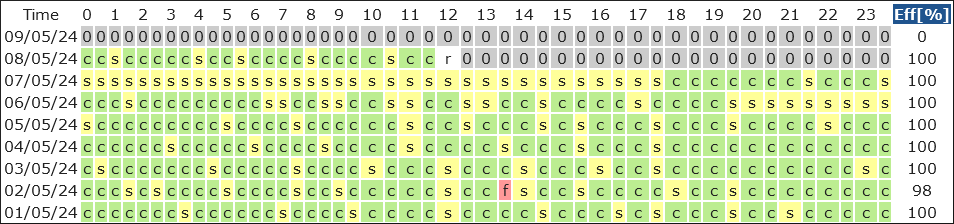
- HC remained in Submitted state for quite some time on 7th, any reason for this ? do we have some reserved slots for HC tests ?
- 
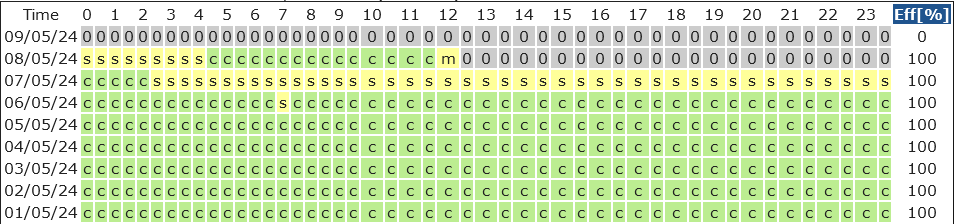
- 
#
## 01-05-2024
- Some important links - [Sites status board](https://cern.ch/ukcloud-site-status-board), [weekly status](https://cern.ch/ukcloud-weekly-site-status), [JobAccountDashboardUKCloud](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17#), [Open ggus tickets](https://cern.ch/open-ggus-tickets-ngi-uk-atlas)
- No open tickets
- RPG replication (ongoing) 4.3PB more to go as of last week
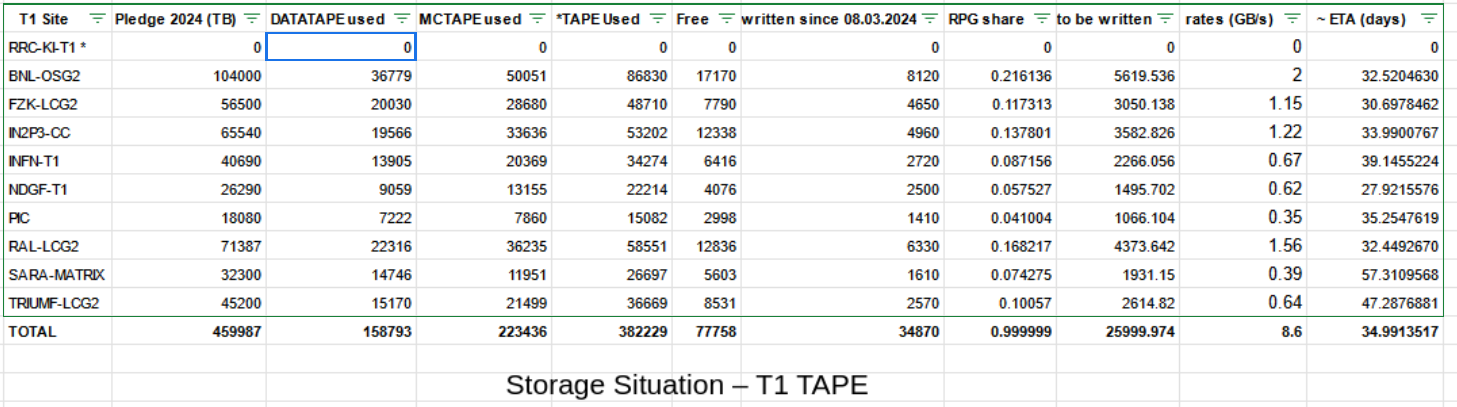
- Antares upgrade - no effect seen on ATLAS side.
- RAL ATLAS Tier1(RAL-LCG2) Availability/Reliabiity for the past week - **100%** [Link](https://monit-grafana.cern.ch/goto/8WmaqYBIg?orgId=17)
- CPU slot occupancy average vs pledge during last week - **~88%** [Link](https://monit-grafana.cern.ch/d/Ik2RpnYnk/job-accounting-uk-cloud?orgId=17)
- Walltime job efficiency **~97%**[Link](https://monit-grafana.cern.ch/goto/7EnYyrBIg?orgId=17)
- Data Transfer efficiency **~98 [Link](https://monit-grafana.cern.ch/goto/7EnYyrBIg?orgId=17)
- RAL-LCG2_DATATAPE(TB) Total Capacity - 27077.78, Occupancy - 22309.39
- Occupancy at **~82%** [Link](http://adc-ddm-mon.cern.ch/ddmusr01/plots/plots.php?endpoint=RAL-LCG2_DATATAPE)
- RAL-LCG2_MCTAPE(TB) Total Capacity - 44309.22, Occupancy - 36167.73
- Occupancy at **~82%** [Link](http://adc-ddm-mon.cern.ch/ddmusr01/plots/plots.php?endpoint=RAL-LCG2_MCTAPE)
- RAL-LCG2-ECHO_DATADISK(TB) Total Capacity-25494.00, Occupancy - 25175.26
- Occupancy at **~98%** [Link](http://adc-ddm-mon.cern.ch/ddmusr01/plots/plots.php?endpoint=RAL-LCG2-ECHO_DATADISK)
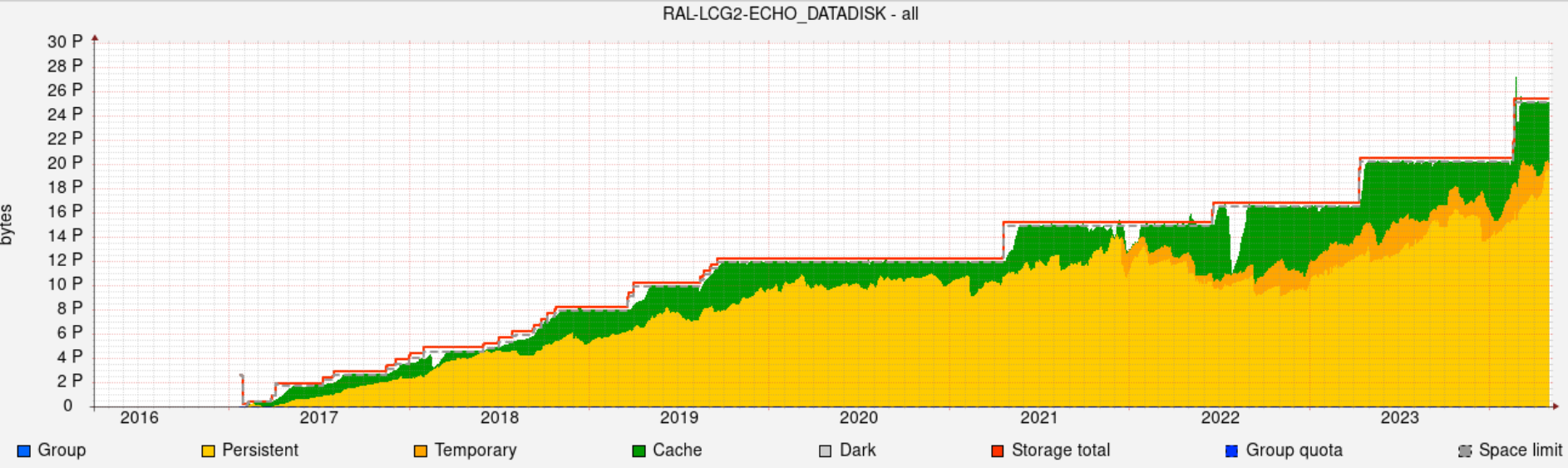
- Job pressure 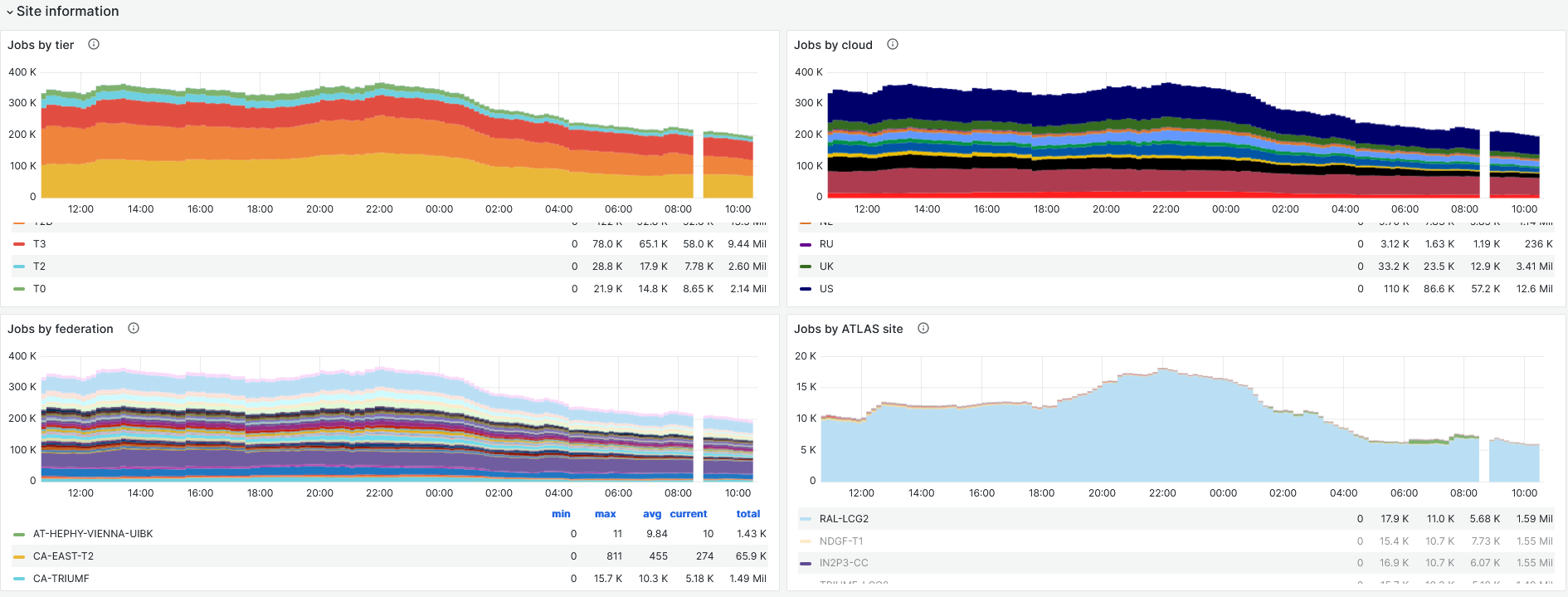
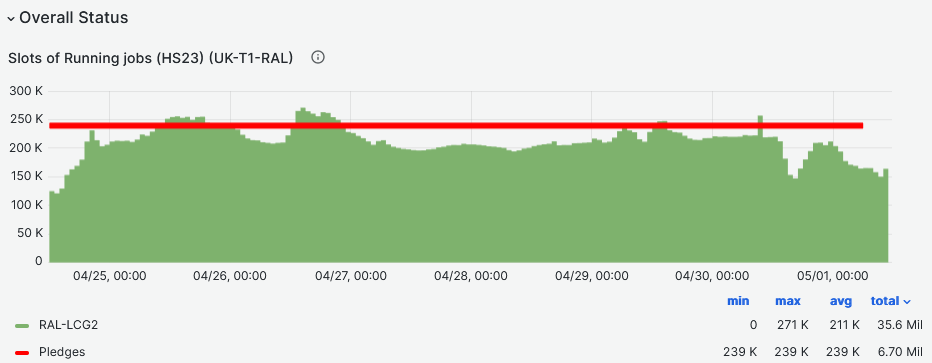
- Occupancy
- Job failure WNs (TBD) https://bigpanda.cern.ch/wns/RAL/?days=7